This is a Plain English Papers summary of a research paper called Smarter Image AI: Dynamic Compression Beats Fixed Limits in Diffusion Models. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: The Problem with Fixed Compression in Diffusion Models
Diffusion Transformer (DiT) models have become the cornerstone of modern image and video generation, powering systems like Stable Diffusion 3, Flux, and CogvideoX. These models offer both transformer scalability and powerful diffusion modeling capabilities. However, they share a critical limitation: they apply fixed compression across all image regions, disregarding the natural variation in information density.
The typical two-stage pipeline in these models first uses a Variational Autoencoder (VAE) to compress the image into a low-dimensional latent space, then further patches this representation for diffusion modeling within a transformer architecture. This spatial compression significantly reduces image sequence length, allowing the transformer to better model global structures.
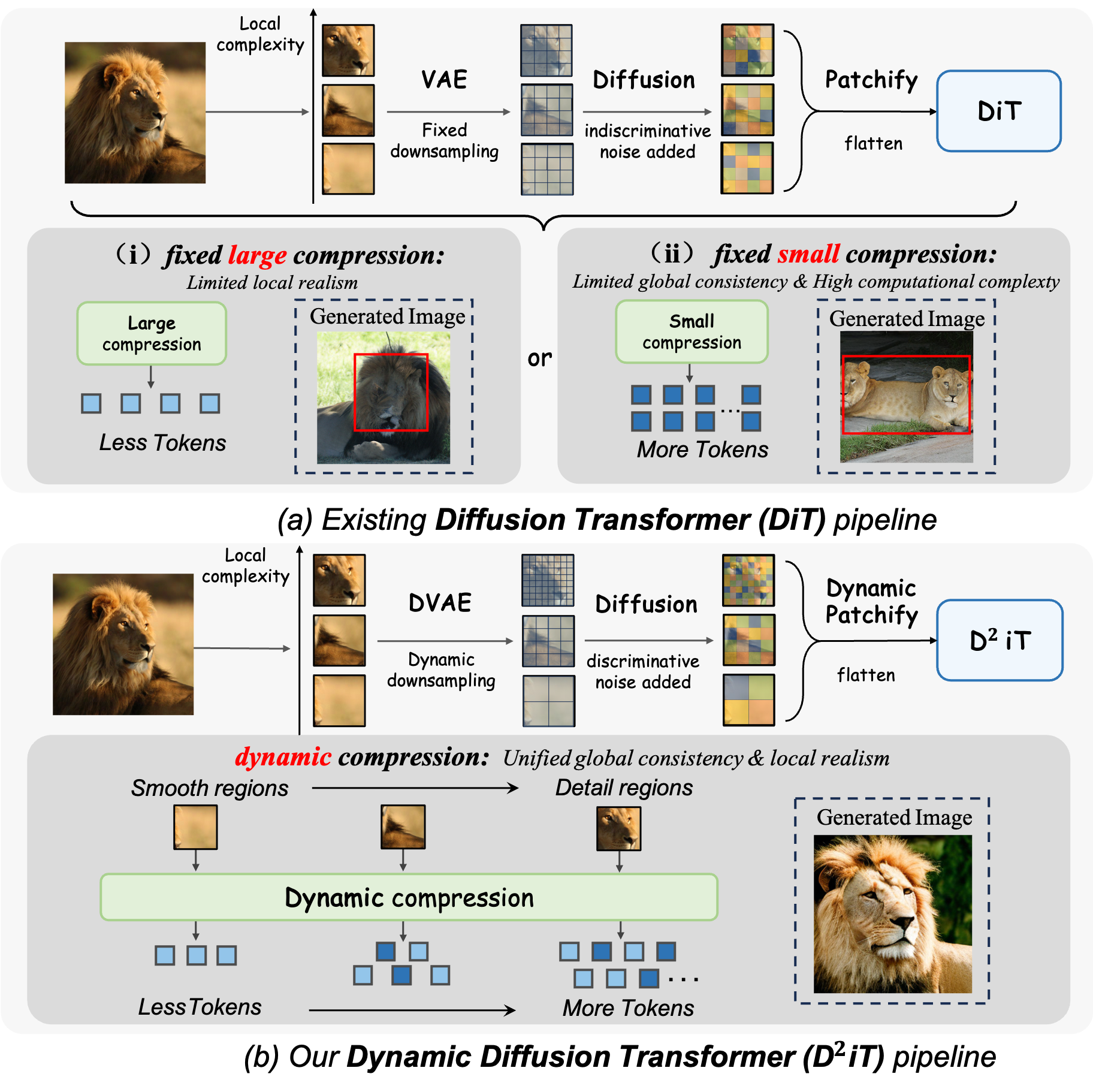
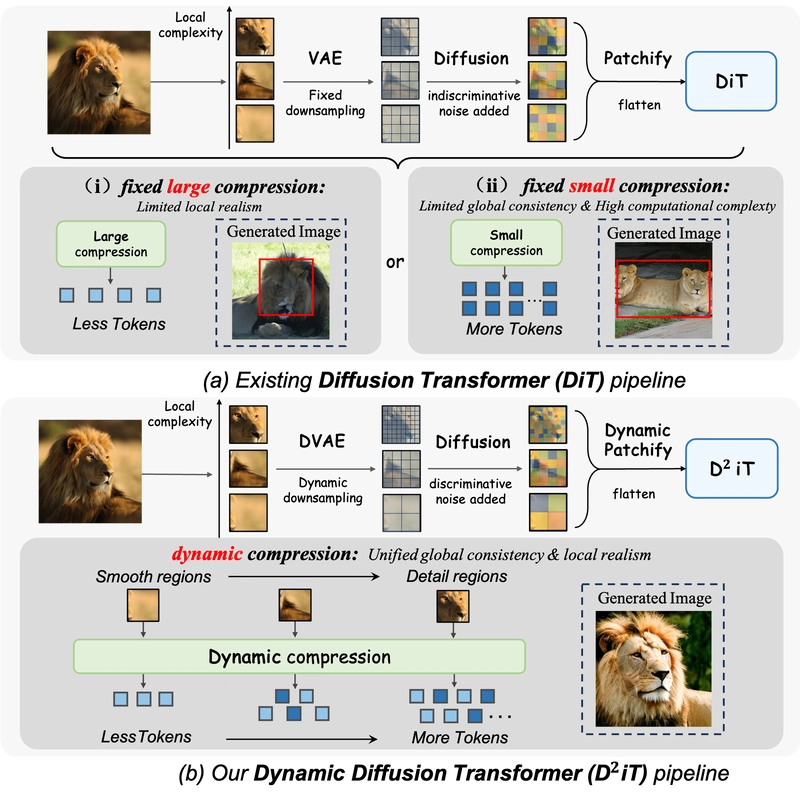
Illustration of our motivation. Compression here refers to the VAE + Patchify operation. (a) Existing fixed-compression diffusion transformer (DiT) ignores information density. Fixed large compression leads to limited local realism due to the limited representation of a few tokens preventing accurate recovery of rich information, whereas fixed small compression leads to limited global consistency and high computational complexity due to the burden of global modeling across patched latents. (b) Our Dynamic Diffusion Transformer (D²iT) adopts a dynamic compression strategy and adds multi-grained noise based on information density, achieving unified global consistency and local realism.
The fundamental problem is that fixed compression treats all image regions equally, ignoring their naturally varying complexity. This creates an inherent tradeoff: large fixed compression helps capture global dependencies but fails to accurately recover rich details in complex regions, while small fixed compression better preserves local details but increases computational burden and compromises global consistency.
To address these limitations, researchers have developed Dynamic Diffusion Transformer (D²iT), a novel two-stage framework that dynamically compresses different image regions based on their information density. This approach aims to achieve both global consistency and local realism by applying appropriate compression levels where needed.
Related Work
2.1 Variational Autoencoder for Generation Models
Variational Autoencoder (VAE) serves as a compression coding model that compactly represents images and videos in latent space. Most current generation models use a two-stage paradigm: first compressing the input into latent space via VAE, then modeling the distribution within this lower-dimensional space. This approach has become prevalent in milestone models like DALL-E, latent diffusion, and Sora.
However, standard VAEs apply fixed-length coding regardless of information density. This means detailed regions receive the same number of coding tokens as background areas, leading to inefficient representation with insufficient coding for important details and redundant coding for simple regions. Previous work proposed dynamic coding VAE for autoregressive models, but D²iT represents the first application of dynamic coding to diffusion models in continuous space.
This approach differs significantly from prior work like DiffIT: Diffusion Vision Transformers for Image Generation, which still uses fixed compression ratios.
2.2 Diffusion Models
Diffusion models have emerged as effective generative approaches that gradually produce denoised samples by learning the denoising process. They've demonstrated remarkable potential in generating high-quality images and advancing progress across various domains. Recent improvements in sampling methods and classifier-free guidance have further enhanced their capabilities.
Latent Diffusion Models (LDMs) adopt a two-stage architecture that efficiently encodes images using pre-trained autoencoders and performs diffusion in low-dimensional latent space. This addresses challenges associated with pixel-space generation. The current work develops a dynamic grained denoising network and verifies its applicability within the Dynamic Diffusion Transformer framework.
D²iT: Dynamic Diffusion Transformer
Standard DiT models apply uniform denoising to fixed-size image regions, making it difficult to balance global consistency with local detail preservation. Recognizing that natural images contain regions of varying perceptual importance, D²iT introduces a two-stage framework to learn dynamic priors.
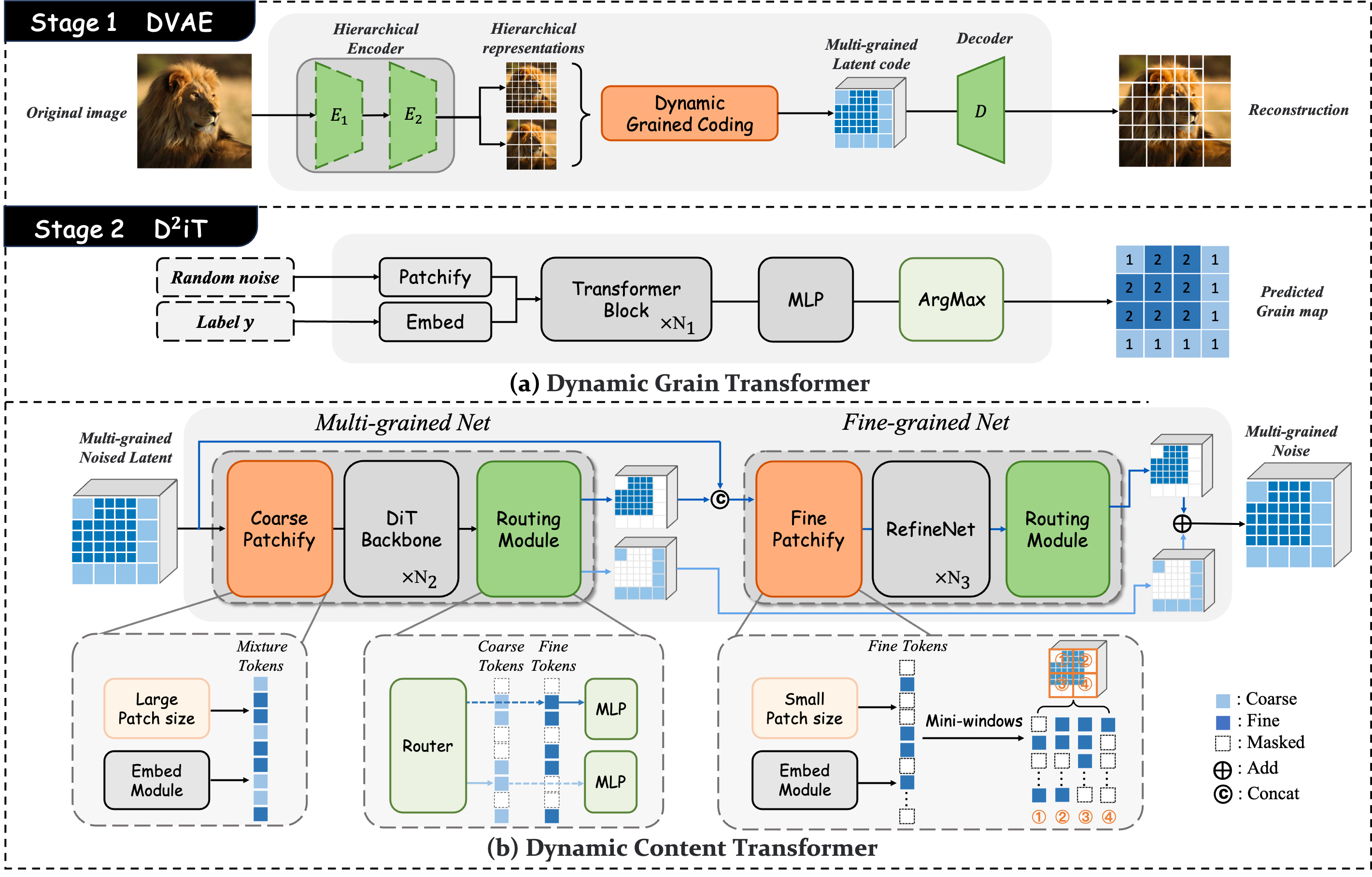
The overview of our proposed two-stage framework. (1) Stage 1: DVAE dynamically assigns different grained codes to each image region through the Hierarchical Encoder and Dynamic Grained Coding (DGC) module. (2) Stage 2: D²iT consists of Dynamic Grain Transformer and Dynamic Content Transformer, which respectively model the spatial granularity information and content information. We present the network with two granularities. The grain map uses '1' to denote coarse-grained regions and '2' for fine-grained regions.
The first stage, Dynamic VAE (DVAE), identifies information density and uses different downsampling rates for different regions. The second stage, D²iT, learns the spatial density information and content information of the multi-grained codes to generate images more naturally.
3.1 Dynamic VAE (DVAE)
Unlike existing VAE-based approaches that use a fixed downsampling factor to represent image regions, DVAE defines a set of staged downsampling factors {f₁, f₂, ..., fₖ}, where f₁ < f₂ < ... < fₖ. An input image is first encoded into grid features through a hierarchical encoder, with each feature level corresponding to a different downsampling factor.
Using the maximum downsampling factor fₖ, the original image is segmented into regions. The Dynamic Grained Coding module then allocates the most suitable granularity to each region based on local information entropy, resulting in a multi-grained latent representation.
This module employs Gaussian kernel density estimation to analyze pixel intensity distributions within each region and uses Shannon entropy to quantify complexity. To handle the irregular latent code with different grained regions, a simple neighbor copying method is implemented, where latent codes for each region are copied to the finest granularity if not already assigned.
This approach fundamentally differs from previous work like DyDiT: Dynamic Diffusion Transformers for Efficient Visual Generation by focusing on information density rather than just computational efficiency.
3.2 Dynamic Diffusion Transformer (D²iT)
The Dynamic Diffusion Transformer consists of two key components:
Dynamic Grain Transformer: Models spatial information complexity distribution and predicts a grain map for the entire image. The ground truth grain map used for training comes from the outputs of the Dynamic Grained Coding module within DVAE.
Dynamic Content Transformer: Performs multi-grained noise prediction using the spatial information provided by the grain map. It consists of a Multi-grained Net for rough prediction and a Fine-grained Net for fine-grained correction.
This two-step approach first predicts the spatial distribution of information complexity, then performs multi-grained diffusion within this naturally informed spatial distribution. This allows for better representation of inherent characteristics in natural images, achieving a balance between global consistency and local detail preservation.
The D²iT architecture represents a significant advancement over standard fixed-compression approaches used in previous DiT models.
Experimental Results
4.1 Implementation Details
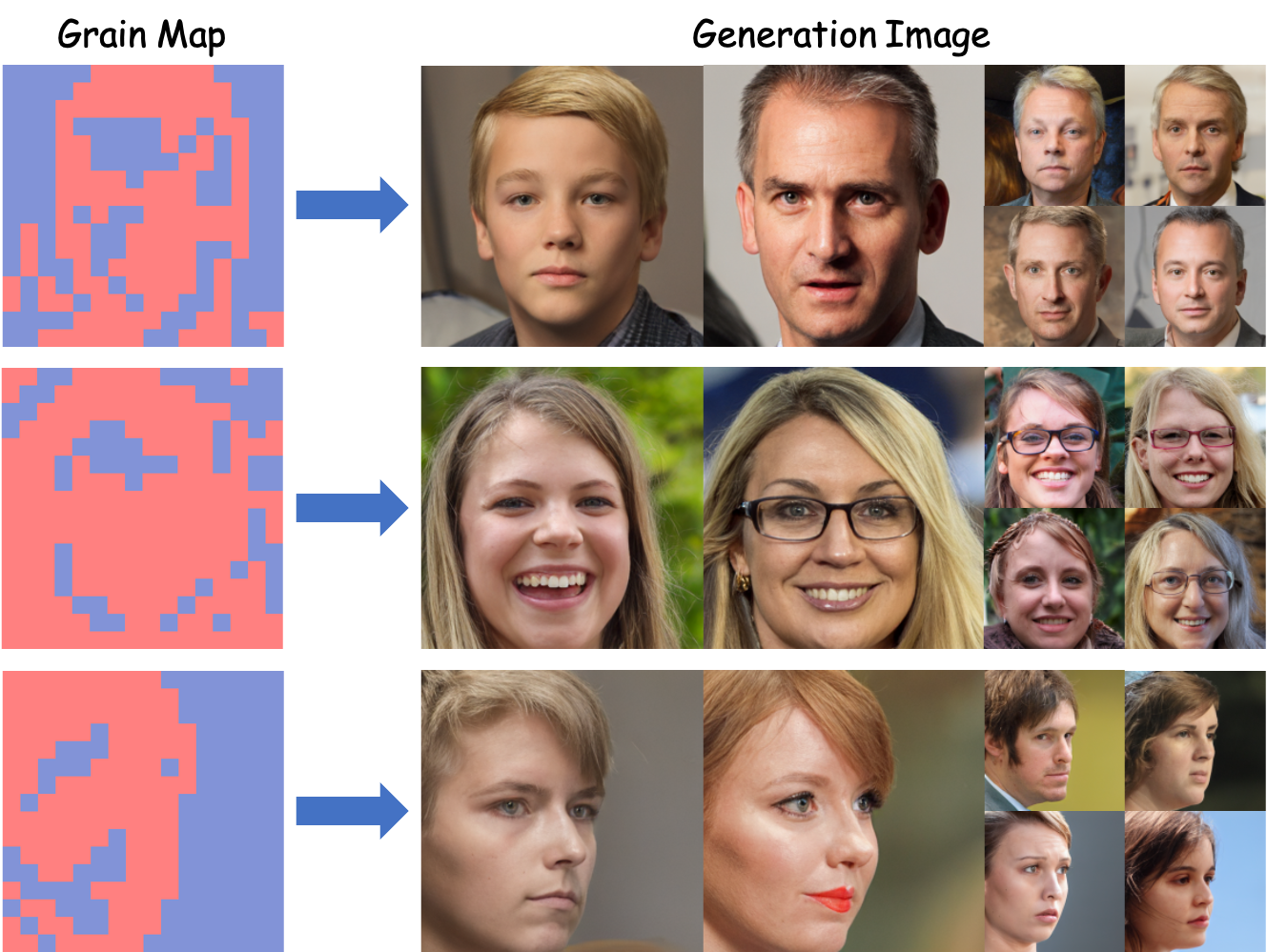
Qualitative results of our unconditional generation on FFHQ. In the grain map, red blocks represent fine-grained regions, while blue blocks indicate coarse-grained regions.
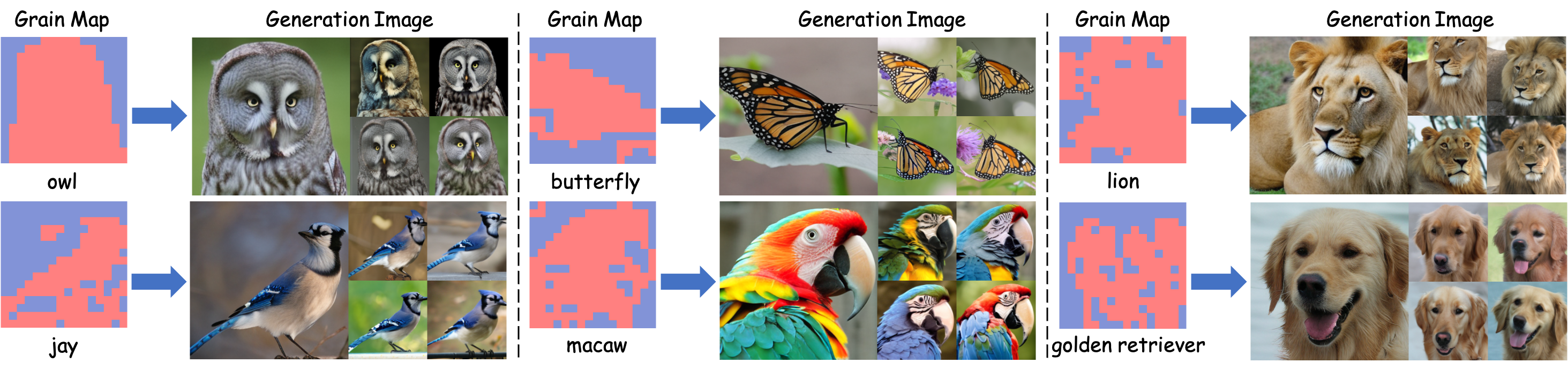
Qualitative results of D²iT-XL on ImageNet. The grain maps are generated by the Dynamic Grain Transformer based on class labels, and the images are generated by the Dynamic Content Transformer based on class labels and grain maps.
The implementation uses two grains to align with previous work. In the first stage, the hierarchical encoder in DVAE downsamples by factors of F={8,16} to achieve reasonable compression, with detail regions using 8× downsampling and smooth regions using 16× downsampling. For a 256×256×3 RGB image, this produces a dual-grained mixture representation of 32×32×4 and 16×16×4, with coarse-grained codes copied to corresponding positions to combine the grains.
The Dynamic Grain Transformer follows DiT-S settings with 33M parameters. The Dynamic Content Transformer has three variants: D²iT-B (base model, 136M parameters), D²iT-L (large model, 467M parameters), and D²iT-XL (extra-large model, 687M parameters). The Multi-grained Net and Fine-grained Net use patch sizes of 2 and 1, respectively.
Training used the AdamW optimizer with a batch size of 256 and a learning rate of 1×10⁻⁴, maintaining an exponential moving average of weights with a decay rate of 0.9999. All models were trained on eight A800 GPUs.
The evaluation used standard benchmarks: unconditional FFHQ and class-conditional ImageNet at 256×256 resolution. Metrics included Fréchet Inception Distance (FID), Inception Score (IS), Precision, and Recall.
| Model Type | Method | Param(M) | FID-10K ↓ |
|---|---|---|---|
| GAN | VQGAN [9] | 307 | 11.4 |
| GAN | ViT-VQGAN [57] | 738 | 13.06 |
| VAE | VDVAE [5] | 115 | 28.5 |
| Diffusion | ImageBART [8] | 713 | 9.57 |
| Diffusion | UDM [20] | - | 5.54 |
| Diffusion | LDM-4 [44] | 274 | 4.98 |
| Diffusion | DiT-L [38] | 458 | 6.26 |
| Diffusion | D²iT-L(ours) | 467 | 4.47 |
Comparison of unconditional generation on FFHQ.
4.2 Comparison with State-of-the-Art Models
For unconditional generation on FFHQ, D²iT-L achieved a 28.6% improvement over DiT-L with an FID-10K score of 4.47. The qualitative results demonstrate that the information density distribution of generated images aligns well with the grain map, confirming the effectiveness of the Dynamic Content Transformer.
For class-conditional generation on ImageNet, D²iT outperformed DiT and other models, achieving an FID score of 1.73 and a 23.8% improvement over DiT-XL using only 57.1% of the training steps. This demonstrates both effectiveness and training efficiency.
| Method | Param(M) | FID-50K ↓ | IS ↑ | Prec. ↑ | Rec. ↑ |
|---|---|---|---|---|---|
| VQGAN [9] | 397 | 15.78 | 78.3 | - | - |
| MaskGIT [1] | 227 | 7.32 | 156.0 | 0.78 | 0.50 |
| DQ-Transformer [15] | 655 | 5.11 | 178.2 | - | - |
| LlamaGen [51] | 775 | 2.62 | 244.1 | 0.80 | 0.57 |
| DiGIT [60] | 732 | 3.39 | 205.96 | - | - |
| Open-MAGVIT2-XL [34] | 1500 | 2.33 | 271.77 | 0.84 | 0.54 |
| VAR [53] | 600 | 2.57 | 302.6 | 0.83 | 0.56 |
| ADM [7] | 554 | 10.94 | 100.98 | 0.69 | 0.63 |
| LDM-4 [44] | 400 | 10.56 | 103.49 | 0.71 | 0.62 |
| DiT-XL [38] | 675 | 9.62 | 121.50 | 0.67 | 0.67 |
| MDT[11] | 676 | 6.23 | 143.02 | 0.71 | 0.66 |
| D²iT-XL(ours) | 687 | 5.74 | 156.29 | 0.72 | 0.66 |
| ADM-G [7] | 554 | 4.59 | 186.70 | 0.82 | 0.52 |
| ADM-G-U [7] | 554 | 3.94 | 215.84 | 0.83 | 0.53 |
| LDM-4-G [44] | 400 | 3.60 | 247.67 | 0.87 | 0.48 |
| DiT-XL-G [38] | 675 | 2.27 | 278.24 | 0.83 | 0.57 |
| RDM-G [52] | 848 | 1.99 | 260.45 | 0.81 | 0.58 |
| DiMR [29] | 505 | 1.70 | 289.0 | 0.79 | 0.63 |
| MDT-G[11] | 676 | 1.79 | 283.01 | 0.81 | 0.61 |
| MDTv2-G[11] | 676 | 1.58 | 314.73 | 0.79 | 0.65 |
| D²iT-XL-G(ours) | 687 | 1.73 | 307.89 | 0.87 | 0.56 |
Comparison of class-conditional generation on ImageNet 256×256. -G indicates the results with classifier-free guidance.
4.3 Ablation Studies and Analysis
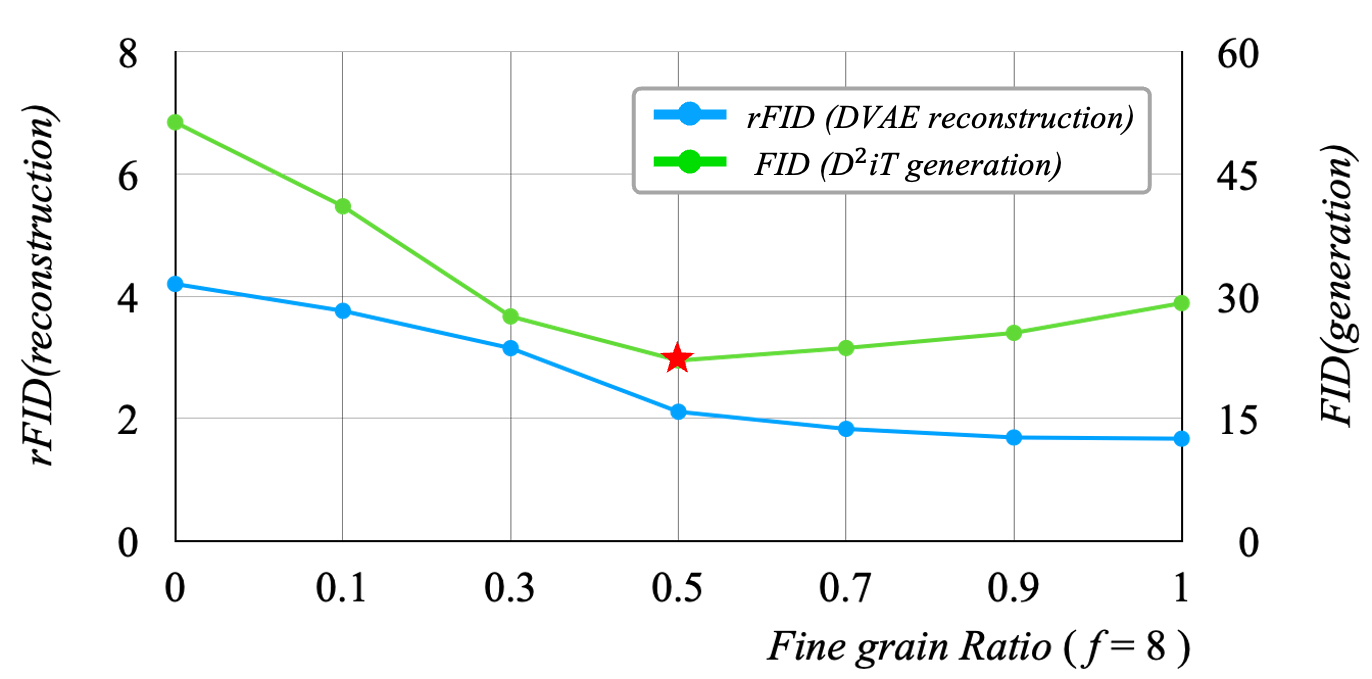
The curves of different grain ratios of reconstruction quality (rFID) to generation quality (FID) on FFHQ.
The dynamic granularity strategy was validated against fixed compression baselines. As the proportion of fine granularity increased, DVAE's reconstruction quality improved due to more codes better representing the image. At an appropriate fine grain ratio (rf=8=0.5), D²iT showed superior image generation ability (FID of 22.11) compared to fixed-level noise (FID of 29.15 for rf=8=1 and 51.33 for rf=8=0).
This confirms that important regions require more coding while less important regions need less, and that using too much code for coarse-grained regions can hinder model performance. When fine grain ratio increased from 0.7 to 1.0, DVAE gained only 0.16 improvement in rFID (1.83 to 1.67), but D²iT's performance declined from 23.64 to 29.15, indicating that the last 30% of less important regions contribute little effective information.
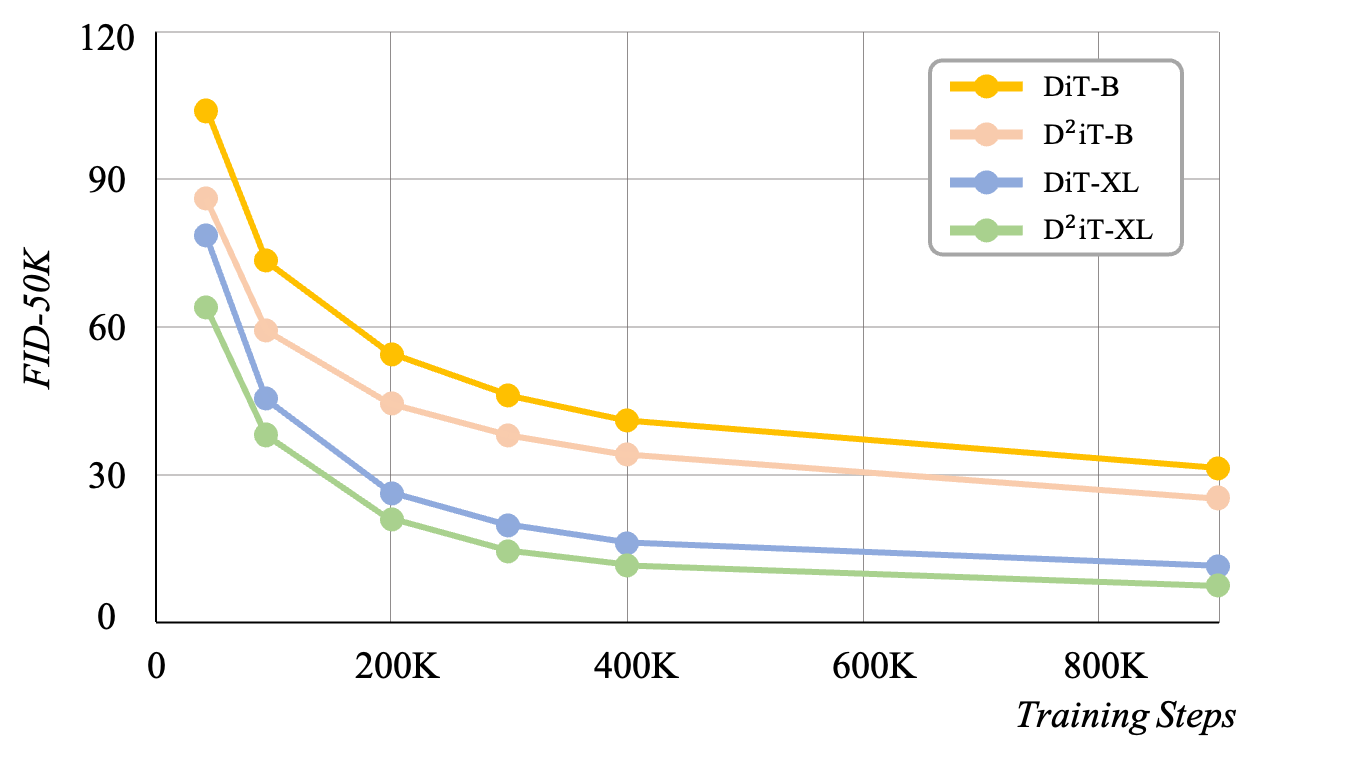
Training convergence comparison of DiT and our D²iT with different parameters on ImageNet. FID-50K is evaluated.
D²iT also demonstrated faster convergence than DiT on ImageNet with models of similar parameters. Various component ablations verified the effectiveness of the design, with progressive improvements from adding DVAE and Routing Module (FID 34.67→29.10), distinguishing losses in different regions (FID 29.10→27.62), and replacing standard DiT layers with RefineNet layers (FID 27.62→22.11).
| Grain Map Setting | FID-10K ↓ |
|---|---|
| Random | 15.93 |
| Ground Truth | 4.35 |
| Dynamic Grain Transformer | 4.47 |
Effect of grain map setting on generation quality.
| Total Layers | DiT | RefineNet | FID-10K ↓ |
|---|---|---|---|
| 12 | 12 | 0 | 25.15 |
| 12 | 10 | 2 | 22.11 |
| 12 | 8 | 4 | 26.53 |
| 12 | 12 | 0 | 25.15 |
| 14 | 12 | 2 | 20.99 |
| 16 | 12 | 4 | 19.96 |
Effect of numbers of RefineNet Blocks in D²iT-B. Experiments with fixed total layers increasing Refinenet layers and fixed DiT layers increasing Refinenet layers.
The RefineNet effectiveness was verified through controlled experiments. When adjusting the ratio of DiT Blocks to RefineNet Blocks while keeping model size constant, processing detail regions enhanced generation capability. The optimal ratio was found to be five DiT layers to one RefineNet layer. Additionally, increasing RefineNet blocks while maintaining DiT blocks demonstrated RefineNet's scaling capabilities.
Conclusion and Future Directions
This research identifies a fundamental limitation in existing Diffusion Transformer models: they apply fixed denoising to uniformly sized image regions, disregarding the naturally varying information densities. This results in insufficient denoising in crucial regions and redundant processing in less significant ones, compromising both local detail authenticity and global structural consistency.
The D²iT framework addresses this by dynamically compressing different image regions based on their information density. The first stage, Dynamic VAE (DVAE), encodes images more accurately by identifying information density and applying different downsampling rates. The second stage, Dynamic Diffusion Transformer, learns both spatial density information and content information to generate images more naturally.
Comprehensive experiments demonstrate significant improvements over existing models, with D²iT-L achieving a 28.6% improvement over DiT-L for unconditional generation and D²iT-XL-G showing competitive performance for class-conditional generation.
Future work could explore using more than two granularities within the dynamic diffusion transformer architecture to further enhance the balance between global consistency and local realism.
