ในยุคสมัยที่การส่งMailเป็นอีกหนึ่งวิธีที่สำคัญในการติดต่อสื่อสาร Mail นั้นนอกจากMailที่เราควรจะได้รับจริงๆ ก็ยังมี Mail ที่เป็น Spam ซึ่งเราอาจจะไม่ต้องการได้รับด้วย ดังนั้นจาก Mail จำนวนมาก ผมจึงได้พบว่าการใช้ TF-IDF และ Logistic Regression สามารถช่วยเราจำแนกMailเหล่านั้นว่าเป็น Spam(ไม่อยากได้รับ) หรือ Ham(อยากได้รับ)ได้
บทความนี้ผมจึงจะพามาดู การใช้ TF-IDF และ Logistic Regression ใน Python โดยรันผ่าน Visual Studio Code กัน ซึ่งผมได้เนื้อหา การใช้งานโค้ด และ Datasetจาก Github Spam-Mail-Detection-using-TF-IDF
ก่อนจะเริ่มกันผมอยากขออธิบาย TF-IDF และ Logistic Regression กันก่อน
TF-IDF หรือ Term Frequency - Inverse Document Frequency
เป็นเทคนิคที่ใช้ ให้ค่าน้ำหนัก กับคำแต่ละคำในเอกสาร โดยพิจารณาว่าคำนั้น
- พบในเอกสารหนึ่งบ่อยแค่ไหน (TF - Term Frequency)
- พบในเอกสารทั้งหมดบ่อยแค่ไหน (IDF - Inverse Document Frequency)
หาด้วยสูตร TF-IDF = TF × IDF
TF = จำนวนคำทั้งหมดในเอกสาร/จำนวนครั้งที่คำปรากฏ
IDF = log(จำนวนเอกสารที่มีคำนั้น/จำนวนเอกสารทั้งหมด)
ตัวอย่างเช่น คำว่า "ฟรี" มีTF(ความถี่ในการใช้) = 0.05 มีIDF(สำคัญแค่ไหน) = 0.3 ก็จะได้ TF-IDF อยู่ที่ 0.15
Logistic Regression เป็น Supervised Learning Algorithm ที่ใช้สำหรับ Binary Classification (เช่น Spam vs. Not Spam) โดยทำนายค่า ความน่าจะเป็น (probability) ของแต่ละคลาส เช่น
- ความน่าจะเป็น > 0.5 → โมเดลทำนายว่าเป็น Spam
- ความน่าจะเป็น < 0.5 → โมเดลทำนายว่าเป็น Not Spam
Dataset ที่ผมจะนำมาใช้มาจากGithubที่กล่าวถึงไปก่อนหน้า โดยใน Dataset จะประกอบด้วย 5572 แถว แต่ละแถวประกอบด้วย 2 คอลัมน์ ดังนี้
[, 1] Category ประเภทของMailว่าเป็น Spamหรือไม่(Spam or Ham)
[, 2] Message เนื้อหาข้อความในMail
ขั้นตอนที่ 1: นำเข้า library ที่จำเป็น
ตัวอย่างการนำเข้าlibrary สามารถ นำเข้าได้ตามนี้เลย
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_scoreขั้นตอนที่ 2: นำเข้าข้อมูล mail_data
ตัวอย่างของการนำเข้าข้อมูลตามนี้เลย
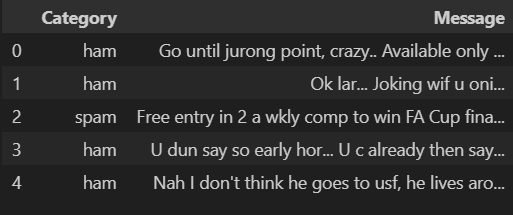
df = pd.read_csv("mail_data.csv")
df.head()ตัวอย่างผลที่ได้จากการรัน
ขั้นตอนที่ 3: จัดการข้อมูล
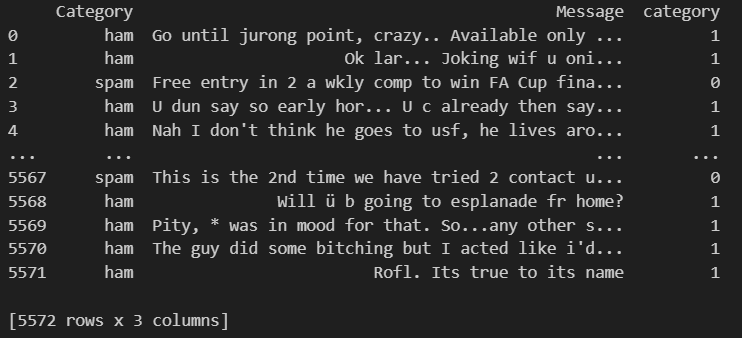
เริ่มจากแทนที่ข้อมูลที่เป็น null ให้เป็น null string ก่อนแล้วสร้างคอลัมน์ใหม่ category ที่เปลี่ยนข้อมูลจากคอลัมน์ที่มีอยู่ Category ที่เป็นคำอย่างSpam,Ham ให้เป็น0,1ตามลำดับ
data = df.where((pd.notnull(df)),'')
data['category'] = data['Category'].apply(lambda x: 1 if x == 'ham' else 0)
print(data)ตัวอย่างผลที่ได้จากการรัน
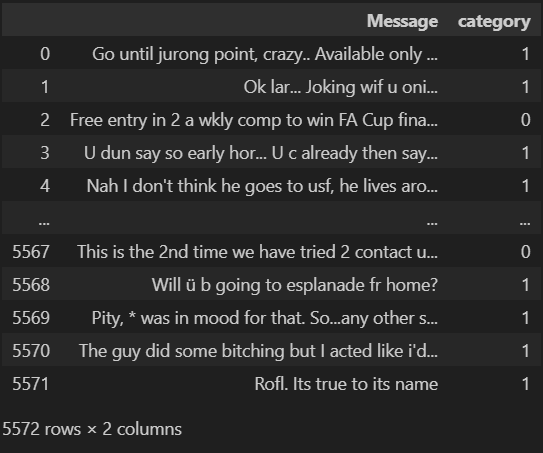
ลบคอลัมน์ Category เดิมที่เป็นคำออกเพื่อใช้เฉพาะคอลัมน์ใหม่ที่เป็นตัวเลขแทน
data.drop(columns=['Category'])ตัวอย่างผลที่ได้จากการรัน
แบ่งข้อมูลออกเป็นสำหรับ train และ test โดยใช้ train_test_split จาก scikit-learn
X = data['Message']
y = data['category']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)ขั้นตอนที่ 4: แปลงข้อความเป็นเวกเตอร์ TF-IDF
ทำการเปลี่ยนข้อความใน Message ให้เป็นเวกเตอร์เพื่อใช้คำนวนหาคะแนนของ TF-IDF ของแต่ละคำ
#Transorm data into feature vectors
# Creating a TfidfVectorizer for feature extraction
feature_extraction = TfidfVectorizer(min_df=1, stop_words='english', lowercase=True)
# Transforming the training data into TF-IDF feature matrix
X_train_feature = feature_extraction.fit_transform(X_train)
# Transforming the test data using the same vectorizer as used for training data
X_test_feature = feature_extraction.transform(X_test)
# Converting the data type of training labels to integer
y_train = y_train.astype('int')
# Converting the data type of test labels to integer
y_test = y_test.astype('int')
print(X_train_feature) # each message gets score by Tfidvectorixerตัวอย่างผลที่ได้จากการรัน
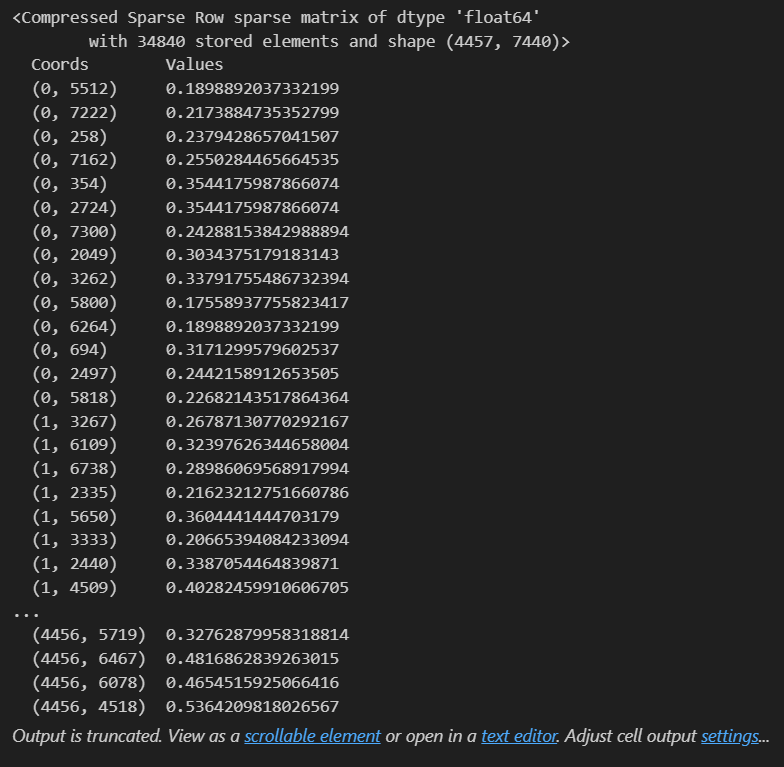
ขั้นตอนที่ 5: Train Model โดยใช้ Logistic Regression
#creating the model
model = LogisticRegression()
model.fit(X_train_feature, y_train)ขั้นตอนที่ 6: การประเมิน
ทำการประเมินความแม่นยำของ Model ทั้งจากข้อมูลสำหรับ train และ test
การประเมินความแม่นยำจากข้อมูลสำหรับ train
# Predicting labels on the training data using the trained model
pred_on_training_data = model.predict(X_train_feature)
# Calculating accuracy on the training data by comparing predicted labels with actual labels
acc_on_training_data = accuracy_score(y_train, pred_on_training_data)
print("Accuracy on training data:",acc_on_training_data)ตัวอย่างผลที่ได้จากการรัน

การประเมินความแม่นยำจากข้อมูลสำหรับ test
pred_on_test_data = model.predict(X_test_feature)
acc_on_test_data = accuracy_score(y_test, pred_on_test_data)
print("Accuracy on test data:",acc_on_test_data)ตัวอย่างผลที่ได้จากการรัน

ขั้นตอนที่ 7: ลองให้ทำนายดู
ให้ Model ลองทำนายว่า Mailที่ใส่ไปจะเป็น Spamหรือไม่
input_your_mail = ["Hi frnd, which is best way to avoid missunderstding wit our beloved one's?"]
input_data_features = feature_extraction.transform(input_your_mail)
prediction = model.predict(input_data_features)
if(prediction[0] == 1):
print("Ham mail")
else:
print("Spam mail")ตัวอย่างผลที่ได้จากการรัน
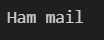
ผลออกมาว่าเป็น Ham mailแสดงว่า ผลทำนายคือไม่ใช่Spam mail หรือก็คือเป็นMailที่สำคัญ
ตัวอย่างเพิ่มเติม
ทีนี้ผมจะลองเปลี่ยนข้อมูลในDataset ให้เป็นภาษาไทยดู โดยในDataset จะมีทั้งหมด 245 แถวแต่ละแถวประกอบด้วย 2 คอลัมน์ ดังนี้
[, 1] Category ประเภทของMailว่าเป็น Spamหรือไม่(Spam or Ham)
[, 2] Message เนื้อหาข้อความในMailเป็นภาษาไทย
ขั้นตอนที่ 1: นำเข้า library ที่จำเป็น
ตัวอย่างการนำเข้าlibrary สามารถ นำเข้าได้ตามนี้เลย
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_scoreขั้นตอนที่ 2: นำเข้าข้อมูล mail_data
ตัวอย่างของข้อมูลได้ตามนี้เลย โดยจะเพิ่มเติมจากตัวอย่างเก่าคือ on_bad_lines="skip" ที่จะข้ามข้อความที่ไม่สามารถใช้ได้ออกไป เพราะเพื่อลดปัญหาที่จะเกิดเมื่อเป็นภาษาไทย
df = pd.read_csv("mail_data.csv ,on_bad_lines="skip")
df.head()ตัวอย่างผลที่ได้จากการรัน

ขั้นตอนที่ 3: จัดการข้อมูล
เริ่มจากแทนที่ข้อมูลที่เป็น null ให้เป็น null string ก่อนแล้วสร้างคอลัมน์ใหม่ category ที่เปลี่ยนข้อมูลจากคอลัมน์ที่มีอยู่ Category ที่เป็นคำอย่างSpam,Ham ให้เป็น0,1ตามลำดับแบบตัวอย่างแรกเลย
data = df.where((pd.notnull(df)),'')
data['category'] = data['Category'].apply(lambda x: 1 if x == 'ham' else 0)
print(data)ตัวอย่างผลที่ได้จากการรัน

แต่ผลที่ได้ออกมาเนื่องจากการที่เปลี่ยนชุดข้อมูลไปแล้ว และเพิ่มการข้ามข้อความที่ใช้ไม่ได้ในขั้นตอนที่2 จึงได้ข้อความที่ใช้ได้มาเพียง 215 จาก 245 แถว
ขั้นตอนที่ 4: แปลงข้อความเป็นเวกเตอร์ TF-IDF
ทำการเปลี่ยนข้อความใน Message ให้เป็นเวกเตอร์เพื่อใช้คำนวนหาคะแนนของ TF-IDF ของแต่ละคำ
#Transorm data into feature vectors
# Creating a TfidfVectorizer for feature extraction
feature_extraction = TfidfVectorizer(min_df=1, stop_words='english', lowercase=True)
# Transforming the training data into TF-IDF feature matrix
X_train_feature = feature_extraction.fit_transform(X_train)
# Transforming the test data using the same vectorizer as used for training data
X_test_feature = feature_extraction.transform(X_test)
# Converting the data type of training labels to integer
y_train = y_train.astype('int')
# Converting the data type of test labels to integer
y_test = y_test.astype('int')
print(X_train_feature) # each message gets score by Tfidvectorixerตัวอย่างผลที่ได้จากการรัน

ขั้นตอนที่ 5: Train Model โดยใช้ Logistic Regression
#creating the model
model = LogisticRegression()
model.fit(X_train_feature, y_train)ขั้นตอนที่ 6: การประเมิน
ทำการประเมินความแม่นยำของ Model ทั้งจากข้อมูลสำหรับ train และ test
การประเมินความแม่นยำจากข้อมูลสำหรับ train
# Predicting labels on the training data using the trained model
pred_on_training_data = model.predict(X_train_feature)
# Calculating accuracy on the training data by comparing predicted labels with actual labels
acc_on_training_data = accuracy_score(y_train, pred_on_training_data)
print("Accuracy on training data:",acc_on_training_data)ตัวอย่างผลที่ได้จากการรัน

การประเมินความแม่นยำจากข้อมูลสำหรับ test
pred_on_test_data = model.predict(X_test_feature)
acc_on_test_data = accuracy_score(y_test, pred_on_test_data)
print("Accuracy on test data:",acc_on_test_data)ตัวอย่างผลที่ได้จากการรัน

ขั้นตอนที่ 7: ลองให้ทำนายดู
ให้ Model ลองทำนายว่า Mailที่ใส่ไปจะเป็น Spamหรือไม่ โดยรอบนี้ใส่ไปเป็นภาษาไทยและเขียนให้เป็น Spam เพื่อทดสอบดู
input_your_mail = ["คุณได้รับรางวัลเงินสด คลิกที่นี่เพื่อรับสิทธิ์ทันที! พร้อมลุ้นรับของแถม"]
input_data_features = feature_extraction.transform(input_your_mail)
prediction = model.predict(input_data_features)
if(prediction[0] == 1):
print("Ham mail")
else:
print("Spam mail")ตัวอย่างผลที่ได้จากการรัน
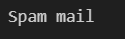
ผลออกมาว่าเป็น Spam mailแสดงว่า ผลทำนายคือเป็นMailที่ไม่สำคัญนั่นเอง
สรุปผล
สำหรับบทความนี้จากที่ผมลองตรวจจับSpam Mailด้วยวิธี TF-IDF เพื่อหาความสำคัญของแต่ละคำ และ Model จาก Logistic Regression ก็ถือว่าให้ผลการทำนายที่ดี ซึ่งสามารถลองนำไปใช้ได้จริงกับภาษาไทยด้วยถึงแม้ว่าต้นแบบจะเป็นภาษาอังกฤษ ก็ตาม ถ้าสนใจก็ลองเอาไปใช้ดูได้เลย
Reference
Spam-Mail-Detection-using-TF-IDF Github:
https://github.com/Ananya01Agrawal/Spam-Mail-Detection-using-TF-IDF
mail_data_thai.csv (ผมสร้างเองเพื่อลองใช้แบบภาษาไทย):
https://github.com/PoundPon/DummyDataset