In today’s digital world, data is being generated at an unprecedented rate, especially in the realm of real-time streaming. From financial transactions and social media feeds to IoT devices and system logs, businesses rely on the continuous flow of data to drive decision-making, enhance user experiences, and improve operational efficiency. However, handling large-scale, high-velocity data streams requires a robust and scalable solution.
Enter Apache Kafka—an open-source event streaming platform designed to process and manage real-time data efficiently. In this guide, we’ll explore what Kafka is, how it works, and why it has become the go-to solution for real-time data streaming across industries. We’ll first start by understanding the main components of Kafka and how each work together to ensure scalability, durability, maintainability, and fault tolerance.
Kafka’s Core Architecture
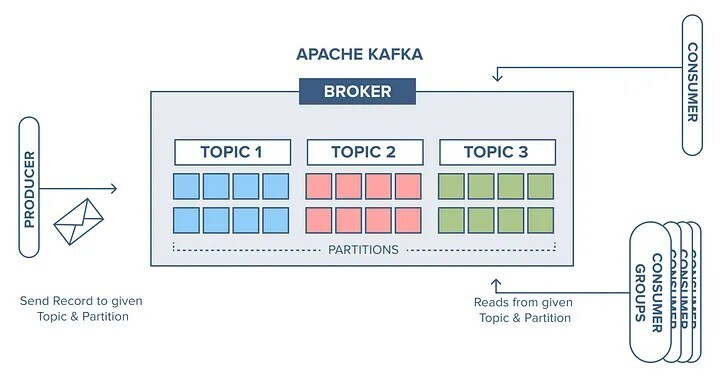
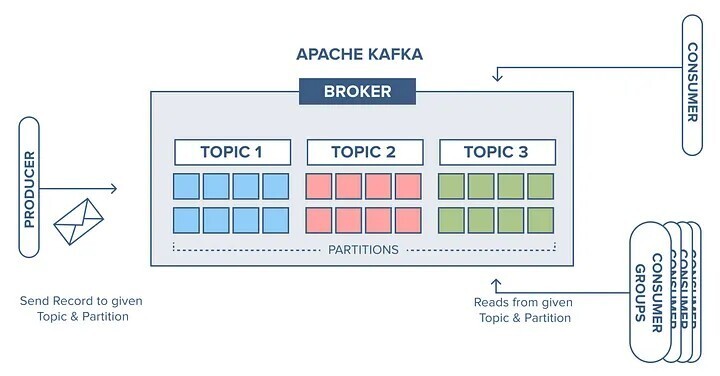
The overall architecture of Apache Kafka revolves around a few key components. Producers, the data sources, push message streams to Kafka brokers—servers that act as intermediaries between producers and consumers. These messages are organized into topics, unique identifiers for data streams, which can be split into partitions to distribute large data volumes across multiple machines in a cluster. A Kafka cluster, a group of brokers working together, can range from a single-broker setup to a multi-broker configuration for enhanced scalability.
Each message in a partition is tagged with an offset, a sequential number unique to that partition, allowing consumers to track and process data in order. Consumers, often grouped into consumer groups to share workloads, subscribe to topics and pull messages from brokers, with offsets ensuring no message is processed twice within the same group. Coordinating this distributed system is Zookeeper, which tracks cluster nodes, topics, partitions, and offsets, ensuring seamless operation.
The Role of the Broker
The broker—In Kafka, a broker is basically a running server. It’s an intermediary between two applications that depend on each other, receiving data from producers and delivering it to consumers with the right permissions. This architecture makes Kafka highly scalable, durable, and fault-tolerant, capable of handling real-time demands across industries.
Running Kafka in Your Environment
To get started with Apache Kafka, Zookeeper is recommended for optimal compatibility. Kafka isn’t natively designed for Windows, so using WSL2 (Windows 10 or later) or Docker is advised.
Here’s how to set it up on Windows with WSL2:
Step 1: Install WSL2
WSL2 (Windows Subsystem for Linux 2) provides a Linux environment on Windows without a VM. Ensure you’re on Windows 10 version 2004 or higher (check with winver). Run this command in an admin PowerShell or Command Prompt, then restart:
wsl --installFollow prompts to set up a Linux distribution (e.g., Ubuntu) and create a user account. Refer to Microsoft Docs if needed.
Step 2: Install Java
Kafka requires Java 11 or 17.
You can find out the available java in your console by running this command.
java --installYou can download either of the versions by running this command
sudo apt install openjdk-17-jre-headless #for java 17if it’s not already on your system.
Step 3: Install Apache Kafka
Download the latest stable version (e.g., 3.7.0 as of February 27, 2024) from the Kafka downloads page.
Run this command to download kafka 3.7.0
wget download_url_from_kafkathen run this command to unzip the zipped file
tar -xzf downloaded_zipped_fileStep 4: Start Zookeeper
Zookeeper, bundled with Kafka, manages the cluster. From the Kafka root directory in a command prompt, run:
bin\zookeeper-server-start.sh config\zookeeper.propertiesStep 5: Start the Kafka Server
In a new command prompt from the Kafka root, launch the server:
bin\kafka-server-start.sh config\server.propertiesStep 6: Create a Topic
Create a topic named “MyFirstTopic” with this command in a new prompt:
bin\kafka-topics.sh --create --topic MyFirstTopic --bootstrap-server localhost:9092Confirm with “Created topic MyFirstTopic.”
Step 7: Start a Producer
Launch a producer to send messages to the topic:
bin/kafka-console-producer.sh --topic MyFirstTopic --bootstrap-server localhost:9092Step 8: Start a Consumer
In another prompt, start a consumer to read messages in real-time:
bin/kafka-console-consumer.sh --topic MyFirstTopic --from-beginning --bootstrap-server localhost:9092Now, messages typed in the producer will appear in the consumer instantly, demonstrating Kafka’s real-time streaming in action.