When you're building with LLMs like Amazon Bedrock's Nova Lite, there's a tough question you'll eventually have to face:
"How do I know my model's answers aren't basically AI Slop?"
We're past the point where eyeballing responses are good enough — we need automated validation at runtime, ideally one that fits neatly into a serverless, production-friendly stack.
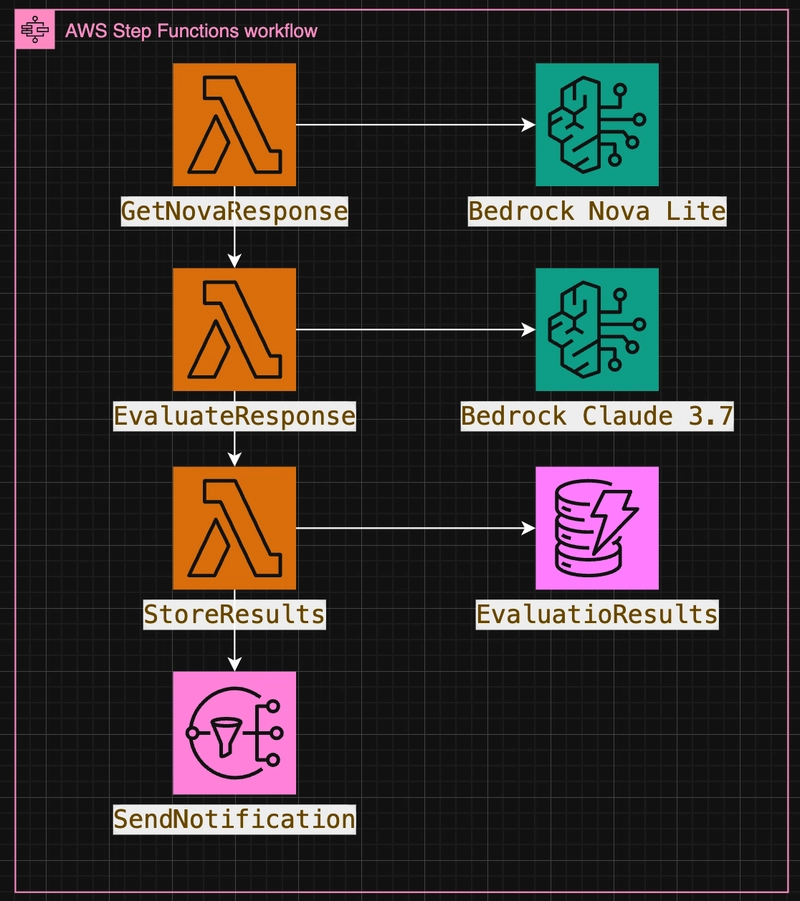
So let's wire up a 100% AWS-native solution:
- ✍️ Nova Lite (via Amazon Bedrock) generates a response
- 📊 Claude or custom Lambda logic evaluates the response
- 🤖 Step Functions + Lambda orchestrate it
- 💾 DynamoDB stores evaluation results
- 🔔 SNS handles notifications
- 🧱 CDK deploys the whole thing
- ✅ And we track responses over time to improve
Let's go full-stack, eval-style baby
🧩 High level architecture
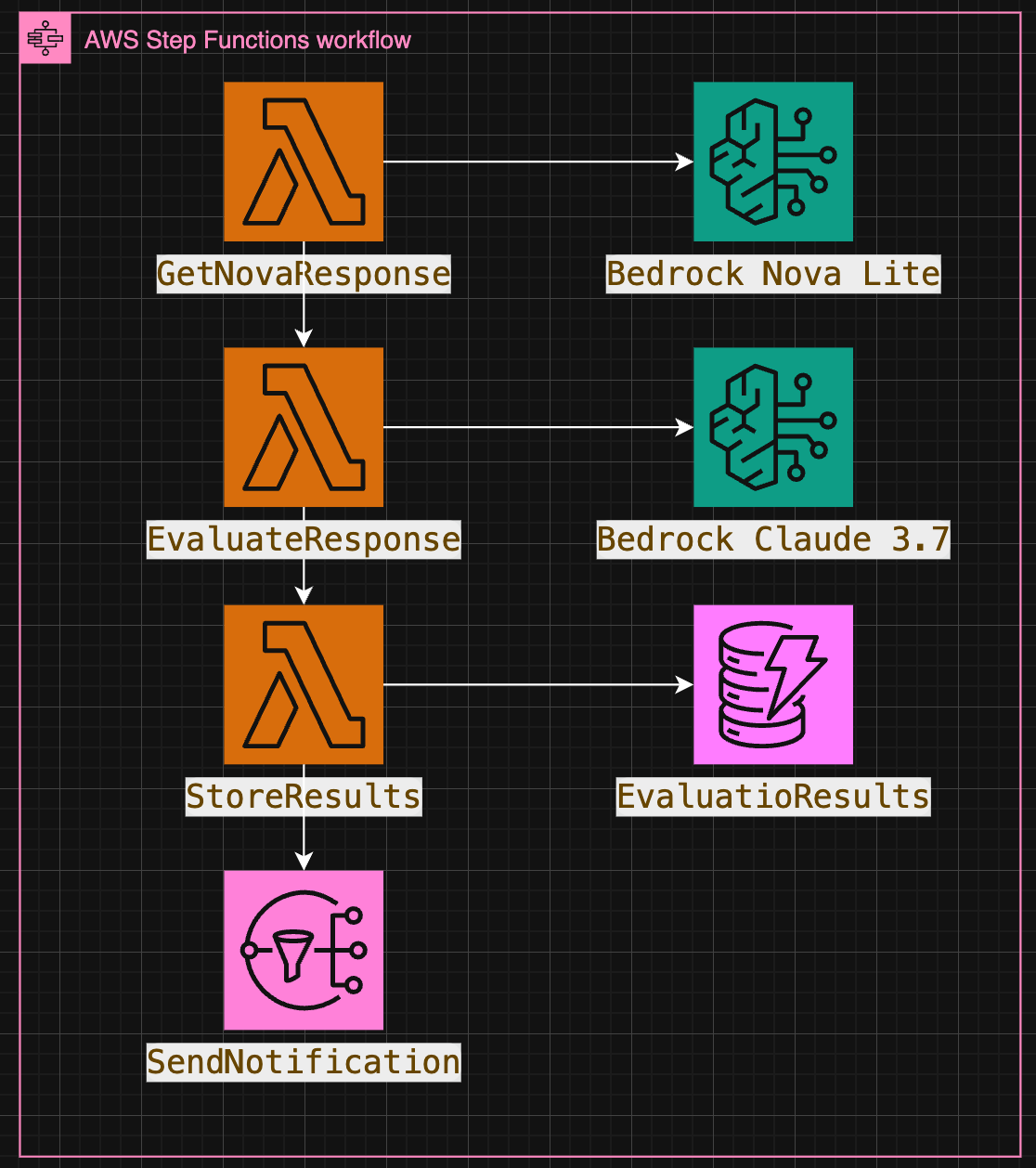
We'll keep things TypeScript down xD
🛠 CDK stack
Here's a bare-bones CDK setup (in TypeScript) to deploy everything:
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as dynamodb from 'aws-cdk-lib/aws-dynamodb';
import * as sns from 'aws-cdk-lib/aws-sns';
import * as snsSubscriptions from 'aws-cdk-lib/aws-sns-subscriptions';
import * as stepfunctions from 'aws-cdk-lib/aws-stepfunctions';
import * as tasks from 'aws-cdk-lib/aws-stepfunctions-tasks';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { Construct } from 'constructs';
export class LlmEvaluationStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// DynamoDB to store evaluation results
const evaluationTable = new dynamodb.Table(this, 'EvaluationResults', {
partitionKey: { name: 'id', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'timestamp', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
});
// SNS Topic for notifications
const evalNotificationTopic = new sns.Topic(this, 'EvalNotificationTopic');
evalNotificationTopic.addSubscription(
new snsSubscriptions.EmailSubscription('[email protected]')
);
// Lambda to get Nova response
const getNovaResponse = new NodejsFunction(this, 'NovaResponseFunction', {
entry: 'lambda/getNovaResponse.ts',
handler: 'handler',
runtime: lambda.Runtime.NODEJS_18_X,
environment: {
REGION: 'us-east-1',
},
});
// Lambda to evaluate the response using Claude or custom logic
const evaluateResponse = new NodejsFunction(this, 'EvaluateResponseFunction', {
entry: 'lambda/evaluateResponse.ts',
handler: 'handler',
runtime: lambda.Runtime.NODEJS_18_X,
environment: {
EVALUATION_TABLE: evaluationTable.tableName,
},
});
// Lambda to store results in DynamoDB
const storeResults = new NodejsFunction(this, 'StoreResultsFunction', {
entry: 'lambda/storeResults.ts',
handler: 'handler',
runtime: lambda.Runtime.NODEJS_18_X,
environment: {
EVALUATION_TABLE: evaluationTable.tableName,
},
});
// Grant permissions
evaluationTable.grantReadWriteData(evaluateResponse);
evaluationTable.grantWriteData(storeResults);
// Step Function to orchestrate the flow
const workflow = new stepfunctions.StateMachine(this, 'EvaluationWorkflow', {
definition: new stepfunctions.Chain()
.start(new tasks.LambdaInvoke(this, 'GetNovaResponse', {
lambdaFunction: getNovaResponse,
outputPath: '$.Payload',
}))
.next(new tasks.LambdaInvoke(this, 'EvaluateResponse', {
lambdaFunction: evaluateResponse,
outputPath: '$.Payload',
}))
.next(new tasks.LambdaInvoke(this, 'StoreResults', {
lambdaFunction: storeResults,
outputPath: '$.Payload',
}))
.next(new tasks.SnsPublish(this, 'SendNotification', {
topic: evalNotificationTopic,
message: stepfunctions.TaskInput.fromJsonPathAt('$.evaluationSummary'),
}))
.next(new stepfunctions.Succeed(this, 'EvaluationComplete')),
});
}
}What does this CDK stack drop?
- 3 Lambdas
- A DynamoDB table
- A Step Function workflow
- A SNS topic
Let's break it down 👇
📦 Lambda 1 — Nova Response (getNovaResponse.ts)
import { BedrockRuntimeClient, InvokeModelCommand } from '@aws-sdk/client-bedrock-runtime';
import { Handler } from 'aws-lambda';
const client = new BedrockRuntimeClient({ region: process.env.REGION || 'us-east-1' });
export const handler: Handler = async (event) => {
const prompt = event.prompt || 'What is the capital of France?';
const expectedAnswer = event.expectedAnswer; // Optional
try {
const params = {
modelId: 'amazon.nova-lite-v1:0',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
inputText: prompt,
textGenerationConfig: {
temperature: 0.2,
maxTokenCount: 300,
}
}),
};
const command = new InvokeModelCommand(params);
const response = await client.send(command);
// Process the response
const responseBody = JSON.parse(new TextDecoder().decode(response.body));
const completion = responseBody.results[0].outputText;
return {
prompt,
completion,
expectedAnswer,
timestamp: new Date().toISOString(),
};
} catch (error) {
console.error('Error invoking Nova:', error);
throw error;
}
};Returns something like:
{
"prompt": "What is the capital of France?",
"completion": "The capital of France is Paris.",
"expectedAnswer": "Paris",
"timestamp": "2025-04-11T17:56:28.000Z"
}
🔍 Lambda 2 — Evaluate with Claude, cuz it's a more opinionated and used model (evaluateResponse.ts)
import { BedrockRuntimeClient, InvokeModelCommand } from '@aws-sdk/client-bedrock-runtime';
import { Handler } from 'aws-lambda';
const client = new BedrockRuntimeClient({ region: process.env.REGION || 'us-east-1' });
export const handler: Handler = async (event) => {
const { prompt, completion, expectedAnswer } = event;
// Build the evaluation prompt for Claude
let evaluationPrompt = `
Evaluate the quality and accuracy of the following AI response:
Question: ${prompt}
Response: ${completion}
`;
if (expectedAnswer) {
evaluationPrompt += `\nExpected answer: ${expectedAnswer}`;
}
evaluationPrompt += `
Evaluation criteria:
1. Factual accuracy (if an expected answer was provided)
2. Relevance to the question
3. Clarity and conciseness
4. Completeness
Provide a score from 0 to 1 (where 1 is perfect) and a brief justification.
Respond only in the following JSON format:
{
"score": [score between 0 and 1],
"passed": [true/false based on score >= 0.7],
"justification": "[brief explanation]"
}
`;
try {
const params = {
modelId: 'anthropic.claude-3-sonnet-20240229-v1:0',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
anthropic_version: "bedrock-2023-05-31",
max_tokens: 1000,
messages: [
{
role: "user",
content: evaluationPrompt
}
]
}),
};
const command = new InvokeModelCommand(params);
const response = await client.send(command);
// Process the response
const responseBody = JSON.parse(new TextDecoder().decode(response.body));
const evaluationText = responseBody.content[0].text;
// Extract JSON from response
const jsonMatch = evaluationText.match(/\{[\s\S]*\}/);
const evaluationResult = jsonMatch ? JSON.parse(jsonMatch[0]) : { score: 0, passed: false, justification: "Failed to parse response" };
return {
...event,
evaluation: {
...evaluationResult,
method: 'claude-evaluation',
},
evaluationSummary: `Evaluation for prompt "${prompt}": ${evaluationResult.passed ? 'PASSED' : 'FAILED'} (Score: ${evaluationResult.score})`
};
} catch (error) {
console.error('Error evaluating with Claude:', error);
throw error;
}
};
💾 Lambda 3 — Store Results (storeResults.ts)
import { DynamoDBClient } from '@aws-sdk/client-dynamodb';
import { DynamoDBDocumentClient, PutCommand } from '@aws-sdk/lib-dynamodb';
import { Handler } from 'aws-lambda';
import { v4 as uuidv4 } from 'uuid';
const client = new DynamoDBClient({});
const docClient = DynamoDBDocumentClient.from(client);
export const handler: Handler = async (event) => {
const { prompt, completion, expectedAnswer, evaluation, timestamp } = event;
const item = {
id: uuidv4(),
timestamp,
prompt,
completion,
expectedAnswer,
evaluation,
modelId: 'amazon.nova-lite-v1:0',
};
try {
await docClient.send(
new PutCommand({
TableName: process.env.EVALUATION_TABLE,
Item: item,
})
);
return {
...event,
storedId: item.id,
message: 'Evaluation stored successfully',
};
} catch (error) {
console.error('Error storing evaluation:', error);
throw error;
}
};📊 Simulated Scenarios
Let's run some examples with more complex situations where Nova might struggle with factual accuracy:
| Prompt | Nova Output | Expected | Eval Score |
|---|---|---|---|
| What was the GDP growth rate of Brazil in Q3 2024? | Brazil's GDP grew by 3.2% in Q3 2024. | Brazil's GDP grew by 1.8% in Q3 2024 | ❌ FAIL |
| Name the 5 permanent members of the UN Security Council | The 5 permanent members are USA, UK, France, Russia, and China. | USA, UK, France, Russia, China | ✅ PASS |
| Who won the Nobel Prize in Physics in 2023? | The 2023 Nobel Prize in Physics was awarded to Peter Higgs for his work on the Higgs boson. | Anne L'Huillier, Pierre Agostini, and Ferenc Krausz | ❌ FAIL |
| What's the most efficient algorithm for finding the shortest path in a weighted graph with negative edges? | Dijkstra's algorithm is the most efficient for finding shortest paths in weighted graphs. | Bellman-Ford algorithm (Dijkstra's doesn't work with negative edges) | ❌ FAIL |
| What medications are contraindicated with Warfarin? | Aspirin, ibuprofen, and some antibiotics are contraindicated with Warfarin. | Partial list but missing key contraindications like certain antibiotics, antifungals, and herbal supplements | ⚠️ PARTIAL |
| Explain the difference between quantum computing and classical computing in one sentence. | Quantum computing uses quantum bits that can exist in multiple states simultaneously, unlike classical bits that can only be 0 or 1. | Reasonable explanation mentioning superposition | ✅ PASS |
| What was the primary cause of the 2008 financial crisis? | The 2008 financial crisis was primarily caused by predatory lending practices and the housing bubble collapse. | Complex answer requiring multiple factors including subprime mortgages, derivatives, lack of regulation, etc. | ⚠️ PARTIAL |
| Write a SQL query to find the second highest salary in a 'employees' table. | SELECT MAX(salary) FROM employees WHERE salary < (SELECT MAX(salary) FROM employees) | Correct SQL query that finds second highest salary | ✅ PASS |
🔁 How to improve When it fails
When your eval fails, here's what you can do:
1. Tune inference settings
- Lower temperature for deterministic answers
- Increase
topPfor broader creativity (only if needed)
2. Improve prompt design
- What's 17 + 26?
+ What's 17 + 26? Answer only with the number3. Upgrade your eval rubric
Use more specific evaluation criteria or customize Claude's evaluation prompt to reflect your domain needs
4. Chain a retry state
In Step Functions, wrap failed evals with a retry flow using a different prompt phrasing or fallback model
That's all folks xD


