Welcome to part one of our Agentic RAG Best Practices series, where we cover how to load, parse, and clean documents for your agentic applications.
This comprehensive guide will teach you how to build effective agentic retrieval applications with PostgreSQL.
Every week, customers ask us about building AI applications. Their most pressing concern isn't advanced chunking strategies or vector databases—it's simply: "How do I clean my data before feeding it to my AI?"
It’s simple: “Garbage in, garbage out.”
Before worrying about writing even your first line of embeddings or retrieval code, you need clean data.
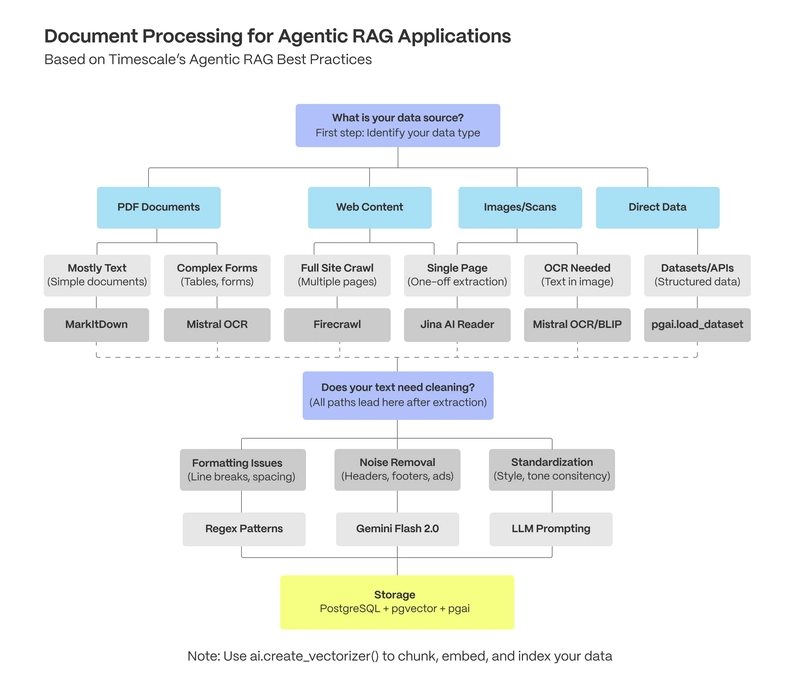
In this first guide of our agentic RAG series, we'll cover gathering the right data, extracting text from various document types, pulling valuable metadata, web scraping techniques, and effectively storing data in PostgreSQL. We'll address common challenges like fixing formatting issues and handling images in documents.
By the end, you'll know how to transform raw documents into clean, structured data that retrieval agents can effectively use.
Don’t want to read all of this and just want to apply it? We have prepared a handy dandy preparation checklist for this topic in a preparation checklist.
One fintech customer recently shared how they spent weeks fine-tuning their RAG application with different vector databases, only to realize their poor results stemmed from simply having dirty data. "I approached the whole thing with like, I don't trust these AIs (. … ) So we don't ask them to make decisions. We do normal modeling to figure out what the user needs, then feed that data to the LLM and just say, 'Summarize it.'"
The garbage in, garbage out principle applies strongly to AI applications. Let's explore how to properly load, parse, and clean your data for AI use.
Gathering the Right Data for AI Applications
👉🏻 Watch the one-minute video summary.
Before even thinking about cleaning or processing your data, you need to make sure you have the right data in the first place. I know, this sounds obvious, but it’s a very important step that many teams overlook in rushing to build their shiny RAG app.
Data selection matters
We have seen many AI teams build state-of-the-art RAG apps that still deliver bad answers. Most of the time, there is nothing wrong with their retrieval algorithm, vector database, embedding model, or large language model. The problem is that they simply don’t have the necessary information in the knowledge base, so the LLM made something up instead or provided insufficient answers.
In most cases, if the information doesn’t exist in your documents, your RAG app should either return nothing (the best-case scenario), or the LLM will simply hallucinate a plausible answer (this is the worst-case scenario).
Choosing the right data
Before building your RAG application, ask yourself and the team these questions:
- What specific questions will users ask the system?
- What documents contain factual information to these questions?
- What are the gaps in our current documentation?
- Is our information up-to-date, or will it need to be regularly updated?
- Do we have a system in place to identify information gaps as users use the app?
You need to be able to confidently answer these questions.
Where to collect data
- Internal knowledge base: Check company wikis, technical documentation, reports, manuals, and databases.
- External sources: Read industry publications, research papers, and public datasets.
- Customer interactions: Check support tickets, chat logs, FAQs, etc.
- Real-time sources: See news feeds, market data, IoT sensor data, etc.
- Intuition: You may have some ideas where certain important data lives, so trust your gut.
Note: Make sure these documents don’t contain sensitive information you don’t want your users to ask about!
Be intentional about your data sources—the higher the quality and relevancy, the better.
Ensure data freshness
Most business data isn't static—it often changes as your products, services, and policies evolve. Outdated information in your RAG system leads to incorrect answers and really hurts your customers’ trust in the AI system (I mean, look at Google’s initial rollout of Bard.)
Consider the following suggestions for keeping your knowledge base up-to-date:
- Set up consistent update schedules: This will be different depending on your business needs. It can be hourly, weekly, monthly, or even quarterly.
- Implement trigger-based updates: Update content whenever the source document changes. For example, when your team updates some documentation, your system should automatically refresh the corresponding knowledge base entries.
- Create document ownership: If you work in a large company, you may need to assign responsibility to other individuals or teams for specific knowledge areas to ensure data is constantly updated.
- Track user feedback: Many RAG systems allow users to rate answers. This rating system (like a simple thumbs up and down) can help identify outdated or incorrect information that needs to be updated, added, or removed from your knowledge base.
- Track question patterns: Continuously analyze questions that consistently receive poor ratings to identify areas where your knowledge base needs improvement.
Data freshness is one of the silent killers of data accuracy—no advanced RAG pipeline can fix this.
Extracting Text From Documents
👉🏻 Watch the one-minute video summary.
Approximately 85 percent of the world's data is unstructured: think PDFs, Word files, emails, PowerPoint presentations, and more. To use this data with AI, you first need to extract the raw text.
Using MarkItDown for Document Conversion
Libraries like MarkItDown and Docling can convert PDFs and other formats to Markdown. Markdown has become one of the cleanest and most efficient formats for ingesting data into LLMs because it's nearly plaintext and token-efficient. It can also efficiently represent non-text data like tables.
Extract text from PDF *using MarkItDown *
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("document.pdf")
text_markdown = result.text_content
print(text_markdown[:500])Extract text from PDF with Optical Character Recognition (OCR) using Docling
# Using Docling for Document Conversion with OCR
from docling.document_converter import DocumentConverter
# Initialize the converter
converter = DocumentConverter()
# Load PDF and extract text with OCR enabled
result = converter.convert(
"document.pdf", # Can be local path or URL
enable_ocr=True # Enable OCR for scanned documents
)
# Get the converted markdown content
markdown_text = result.document.export_to_markdown()
# Preview the first 500 characters
print(markdown_text[:500])The code above returns an object with text_content containing the markdown text, which you can easily pass into your RAG pipeline or LLM for cleaning, analysis, summarizing, or chunking.
Using Visual Language Models for OCR
A new breed of OCR technology is being powered by visual large language models (VLLMs): models that can process not just text, but also images and PDFs. These are trained specifically for unstructured data extraction. One such VLLM making a splash is Mistral OCR.
Extract text and images (in base64) from PDF using Mistral OCR
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2201.04234"
},
include_image_base64=True
)Extract from images using Mistral OCR
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": "https://raw.githubusercontent.com/mistralai/cookbook/refs/heads/main/mistral/ocr/receipt.png"
}
)What makes Mistral OCR unique is its exceptional performance in extracting text in multiple languages, handling text from images, representing math equations, interpreting structured tables, and other traditionally difficult tasks.
Other extraction tools you can experiment with include unstructured.io, olmOCR, or just relying on good ol’ humans to extract the data—Upwork or Fiverr is a good place to begin your search for contractors.
Once you have this more manageable text form, you're ready for either direct ingestion into your database or metadata extraction.
Metadata Extraction
All documents contain metadata like title, author, creation date, length, source, customer name, etc. Imagine needing to fetch all documents between Q1 and Q2 of 2025 for a financial report—you'd need to filter by date range using metadata.
If your PDFs or documents have built-in metadata (added automatically by document processors when saving or exporting), that's great! But what if they don't?
Extracting built-in metadata
For simple metadata extraction from actual PDF data (if available), you can use a library like fitz:
Extract built-in PDF metadata using fitz
import fitz
doc = fitz.open("example.pdf")
metadata = doc.metadata
print(metadata.get("title"), "by", metadata.get("author"))For everything else, you need…
Contextual metadata extraction
Most documents don't have native metadata. In these cases, you need a two-step workflow: first, use a PDF text extractor like Mistral OCR, then pass the raw text to another large language model to request specific information using natural language.
For example, you can use Mistral OCR to analyze each document, define what metadata you'd like to extract (title, author, etc.), and use another LLM to get the metadata information formatted in a specific way (like JSON).
Extract contextual metadata from PDF using Mistral OCR and Mistral Small
import os
from mistralai import Mistral
# Retrieve the API key from environment variables
api_key = os.environ["MISTRAL_API_KEY"]
# Specify model
model = "mistral-small-latest"
# Initialize the Mistral client
client = Mistral(api_key=api_key)
# Define the messages for the chat
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "In JSON format, extract the following metadata from the provided document: title, author, and created data. "
},
{
"type": "document_url",
"document_url": "https://arxiv.org/pdf/1805.04770"
}
]
}
]
# Get the chat response
chat_response = client.chat.complete(
model=model,
messages=messages
)
# Print the content of the response
print(chat_response.choices[0].message.content)
# Save the metadata somewhere for later ingest into your RAG pipelineExtracting Text From the Web
Not all data lives in documents, and not all is accessible via GET API requests. To get data from websites, documentation, and knowledge bases for AI applications, you need to scrape them. The ultimate goal of web scraping is to fetch only the main text content from pages, filtering out headers, footers, sidebars, ads, and tracking scripts, in an LLM-friendly format like Markdown.
In the past, this was done with libraries like requests, Selenium, BeautifulSoup, etc., and required manually setting up proxies to evade rate limiters. Thankfully, it's no longer as painful to scrape the web today (yay!).
Web scrapers generally need to do the following tasks:
- Crawl: Get all pages of an entire website by gathering a list of all internal and external links (essentially building a sitemap, if it’s not available on /sitemap.xml).
- Scrape: Get the DOM/text content of each individual page.
- Proxy : Switch to a different IP to continue on a large crawling and scraping job.
- Clean: Extract the main useful text from the raw DOM.
- Convert: Format the main text content as Markdown, TXT, JSON, etc.
💡
A note about raw DOM : Using a website's HTML is messy because it has ads, menus, and other junk. It also doesn't work well for React apps or other single-page applications.
Firecrawl for Web Scraping
Firecrawl is a web scraping/crawling engine accessible via REST API, Python SDK, and a UI dashboard (currently in beta). What's great about Firecrawl is that it extracts clean page text in various formats. It can crawl an entire site and return all pages' content in one go (with advanced filtering options). It also handles all the proxying needed for large-scale crawl and scrape jobs.
Crawling a website with a limit of 100 pages using Firecrawl Crawl REST API
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Crawl a website:
crawl_status = app.crawl_url(
'https://firecrawl.dev',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)Scraping a URL and outputting in Markdown using Firecrawl Scraping REST API
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_result = app.scrape_url('firecrawl.dev', params={'formats': ['markdown', 'html']})
print(scrape_resultCustom metadata extraction in JSON using Firecrawl Extraction REST API
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
# Initialize the FirecrawlApp with your API key
app = FirecrawlApp(api_key='your_api_key')
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
data = app.scrape_url('https://docs.firecrawl.dev/', {
'formats': ['json'],
'jsonOptions': {
'schema': ExtractSchema.model_json_schema(),
}
})
print(data["json"])💡
_ Author’s note: _ “Firecrawl is one of my favorite SaaS services of 2024. It has awesome docs, affordable pricing, and has a very responsive team. Most importantly, it works really well.” – Jacky Liang
Other Web Scraping Options
Firecrawl isn't the only service/library for crawling, scraping, and cleaning. Another capable service is Jina AI's Reader API, which converts a URL to LLM-friendly inputs simply by adding r.jina.ai in front:
Fetch a webpage in clean Markdown using Jina AI’s Reader API
r.jina.ai/news.ycombinator.comIf you want to build your own end-to-end crawling and scraping infrastructure (expert users only), developers typically use Playwright, a Microsoft framework for web testing and automation. Playwright Web Scraping is a reliable open-source web scraping implementation using Playwright. Firecrawl is also open source and lets you host it in your own infrastructure if you want absolute control.
💡
Pro tip: When running your own web scraping infrastructure, make sure to use proxies for your scraping server to avoid IP bans from websites you're crawling and scraping.
Direct Data Loading
pgai has a handy function that lets you import datasets directly from Hugging Face with just the dataset's name:
Load data from Hugging Face using pgai
SELECT ai.load_dataset('wikimedia/wikipedia', '20231101.en', table_name=>'wiki', batch_size=>5, max_batches=>1, if_table_exists=>'append');pgai has more direct data loading goodies to come—stay tuned.
Storing Data
At Timescale, we believe boutique vector databases are the wrong abstraction for AI workloads. PostgreSQL is the ideal solution for typical apps and AI apps, especially RAG applications.
Instead of using a separate vector database, you can store text embeddings inside PostgreSQL with pgvector. We recommend using pgai to simplify building RAG apps, as we have a handy interface called create_vectorizer() that automatically embeds raw text, chunks it, and continuously keeps it up-to-date.
Create an AI project using pgvector and pgai
// Enable pgai and pgvector on your Postgres database
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS ai;
// Create a table to store Wikipedia articles
CREATE TABLE wiki (
id TEXT PRIMARY KEY,
url TEXT,
title TEXT,
text TEXT
);
// Load Wikipedia dataset directly from HuggingFace
SELECT ai.load_dataset('wikimedia/wikipedia', '20231101.en', table_name=>'wiki', batch_size=>5, max_batches=>1, if_table_exists=>'append');
// Create Vectorizer that
// 1. Chunks the data using the chunking recursive character text splitter
// 2. Embeds it using Mini LM at 384 token size per chunk
// 3. Continuously monitors the wiki table for new text incoming
SELECT ai.create_vectorizer(
'wiki'::regclass,
embedding => ai.embedding_ollama('all-minilm', 384),
formatting=> ai.formatting_python_template('url: $url title: $title $chunk')
chunking => ai.chunking_recursive_character_text_splitter('text'),
);
// Check status of Vectorizxer embedding creation
select * from ai.vectorizer_status;Running the pgai Vectorizer worker
For the vectorizer to work correctly, you need to run the pgai Vectorizer worker alongside your PostgreSQL database. This worker processes your data and creates embeddings. Set up a docker-compose.yml file with the following configuration:
version: '3'
services:
db:
image: timescale/timescaledb-ha:pg17
environment:
POSTGRES_PASSWORD: postgres
ports:
- "5432:5432"
volumes:
- data:/home/postgres/pgdata/data
vectorizer-worker:
image: timescale/pgai-vectorizer-worker:latest
environment:
PGAI_VECTORIZER_WORKER_DB_URL: postgres://postgres:postgres@db:5432/postgres
OPENAI_API_KEY: your_openai_api_key_here
command: ["--poll-interval", "5s"]
ollama:
image: ollama/ollama
volumes:
data:If you're using Ollama for embeddings, as shown in our example, make sure to add the Ollama service and configure the worker:
vectorizer-worker:
environment:
OLLAMA_HOST: http://ollama:11434Start everything with “docker-compose up -d” and the worker will automatically poll the database and process your vectorizer tasks. Note that you might need to adjust settings like poll intervals or concurrency depending on your specific workload needs.
And just like that, we’ve built a production-ready SQL-native retrieval pipeline that is not only powerful but extremely customizable.
Cleaning Messy Data
Raw text extracted from websites or documents is often messy and contains content not relevant to the main text. This can include ads, navigation menus, footers, tracking scripts, or leftover HTML/CSS markup. Removing this noise is crucial to avoid feeding irrelevant text to your AI model, reduce input token size to lower costs, and increase retrieval accuracy.
Cleaning webpages
Elements to clean include:
- HTML tags that aren't content:
,,,, etc. - Advertisements or cookie banners
- Repeated headers/footers on every page
- Excessive whitespace, line breaks, or meaningless Unicode characters
- Images or links to images
The tools mentioned earlier, like Firecrawl and Jina AI's Reader API, already handle webpage data cleaning and return only the main text content.
If you have very specific requirements, you can use web automation frameworks like Playwright or BeautifulSoup to get the raw DOM, then use traditional DOM traversal or regex to clean the data. This approach is for experts only.
Cleaning PDFs
After running documents through Mistral OCR, you'll still have repeated content like page numbers, headers/footers, and repetitive line breaks. A growing technique is using an LLM like Gemini Flash 2.0, which has a two-million-token context window (the largest of all LLMs we've seen) and a reasonable cost to automate cleaning. You can use natural language to instruct it on what to clean: removing repeated titles, sources, footnotes, etc.
You can also clean text manually if you have very specific data requirements.
Fixing Text Formatting
Sometimes text is extracted with poor formatting. You need to standardize lists, headings, and line breaks. You can prompt an LLM to rewrite text more clearly, remove gibberish or irrelevant parts, and correct inconsistencies (without adding extra commentary).
Issues to fix include:
- Line breaks and paragraphs: Merge lines that belong to the same paragraph. For example, replace hyphenated line breaks (
-\n) with nothing, and replace newlines followed by lowercase letters with spaces. - Lists and bullet points: Convert fancy bullet symbols to a common format (e.g., "•" or "–" to "-"). Ensure list items have consistent formatting.
- Headings and subheadings: If using Markdown, ensure headings use # syntax properly with blank lines before and after.
- Whitespace and punctuation: Trim excessive whitespace, normalize quotes and dashes if needed.
- Tone: Standardize tone using large context LLMs like Gemini Flash 2.0 to keep writing style consistent across your text data.
Clean variety of OCR text formatting issues using regex (not an exhaustive example)
import re
def clean_ocr_text(text):
# Replace hyphenated line breaks (e.g., "exam-\nple" -> "example")
text = re.sub(r'(\w)-\n(\w)', r'\1\2', text)
# Merge lines that are broken in the middle of sentences
text = re.sub(r'\n(?=\w)', ' ', text)
# More cleaning steps go here
return textHandling Images in Documents
Some PDFs and web pages have images containing text or are entirely scans of documents. There are several ways to handle these:
- OCR : For scanned documents, OCR can extract text from images. Mistral OCR handles this well.
- MarkItDown : Modern libraries like MarkItDown integrate both OCR and vision models to generate image descriptions.
- BLIP : Models like BLIP (Bootstrapping Language-Image Pre-training) combine understanding images and generating text to give you text descriptions of images.
- Save image URLs : When extracting from webpages, you can save image URLs as text chunks to display in your application.
- Omit images : This is common but not ideal, especially if images contain crucial information like charts or diagrams.
Generate descriptions for images using MarkItDown
from markitdown import MarkItDown
from openai import OpenAI
# Set up OpenAI client
client = OpenAI(api_key="your-openai-api-key")
# Initialize MarkItDown with LLM capabilities
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
# Convert an image file
result = md.convert("path_to_your_image.jpg")
# Print the generated description
print(result.text_content)Generate captions for an image *using BLIP *
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
# Load the pre-trained BLIP model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Open an image file
image_path = "path_to_your_image.jpg" # Replace with your image file path
image = Image.open(image_path)
# Preprocess the image and prepare inputs for the model
inputs = processor(images=image, return_tensors="pt")
# Generate caption
outputs = model.generate(**inputs)
# Decode the generated caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated Caption:", caption)Summarizing or Cleaning Text With an LLM
After programmatic cleaning and parsing, you may still need to refine text further:
- Summarize long documents into shorter summaries or key points.
- Make tone and format consistent.
Simple prompts like "Remove any unnecessary information (like boilerplate) from the following text and correct any errors" or "Summarize the following document in three sentences" can help. If possible, double-check this work, as LLMs can sometimes misinterpret context.
Summarize a piece of text using Gemini Flash 2.0 ** **
from google import genai
from google.genai.types import HttpOptions
client = genai.Client(http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents="Summarize in a technical tone the following piece of text: Attention Is All You Need...",
)
print(response.text)Conclusion
We hear it from our customer’s AI teams all the time. They had spent months trying different vector databases, embedding models, and chunking strategies without seeing any improvement in their RAG application. After a quick data review, we discovered their PDFs were being processed with poor OCR, resulting in garbled text full of artifacts. Within a week of implementing proper data cleaning, their application performance jumped dramatically.
There’s a very important lesson here: Before you worry about the latest bleeding-edge GraphRAG techniques, make sure your data foundation is solid ; this step starts way before you write a single line of RAG code. Clean, well-structured, and high-quality data is the foundation of any successful AI application. As we like to say, “Garbage in, garbage out.”
Start with good data, and the rest of your AI pipeline will fall into place. You need to invest time in proper document gathering, loading, parsing, and cleaning, which will pay dividends in more accurate, relevant, and useful AI outputs.
In the next installment of RAG Best Practices, we will be exploring chunking strategies, followed by embedding generation, indexing techniques, performance optimizations, and more.
Get Involved
Whether you're new to AI or an experienced developer looking to implement agentic RAG with PostgreSQL, this series will give you the foundation you need.
Stay tuned for our next guide on chunking strategies, coming in two weeks.
Connect With Us
Have questions about building agentic RAG apps with PostgreSQL? We're here to help:
- Join our Discord Community : Get real-time answers from the Timescale team and connect with other developers.
- Follow us on social media : Stay updated with the latest from Timescale on X/Twitter and LinkedIn.
- Connect with Jacky ( developer advocate ): Follow me for more practical AI and PostgreSQL content on X/Twitter, Threads, and TikTok.
- Direct questions : Have a specific question about your agentic retrieval implementation? Ask me anything at jacky (at) timescale (dot) com.
We're building this guide for you, so don't hesitate to let us know what topics you'd like us to cover in future installments!


