Introduction
So, what is connection pooling? If you’re a backend developer working with databases, you've likely heard this term. You might have also come across advice on the internet suggesting that instead of opening and closing a connection to the database every time, you should use connection pooling in your application. But why? What are the benefits?
Let’s dive deep into:
- Normal Database Interaction
- Connection Pooling
- Things to Consider When Using Connection Pooling
- Conclusion
Normal Database Interaction
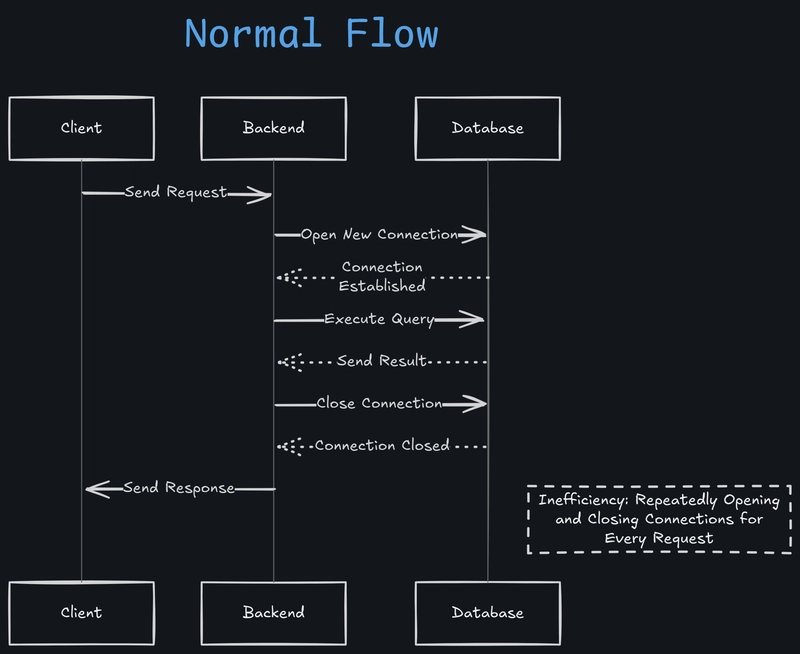
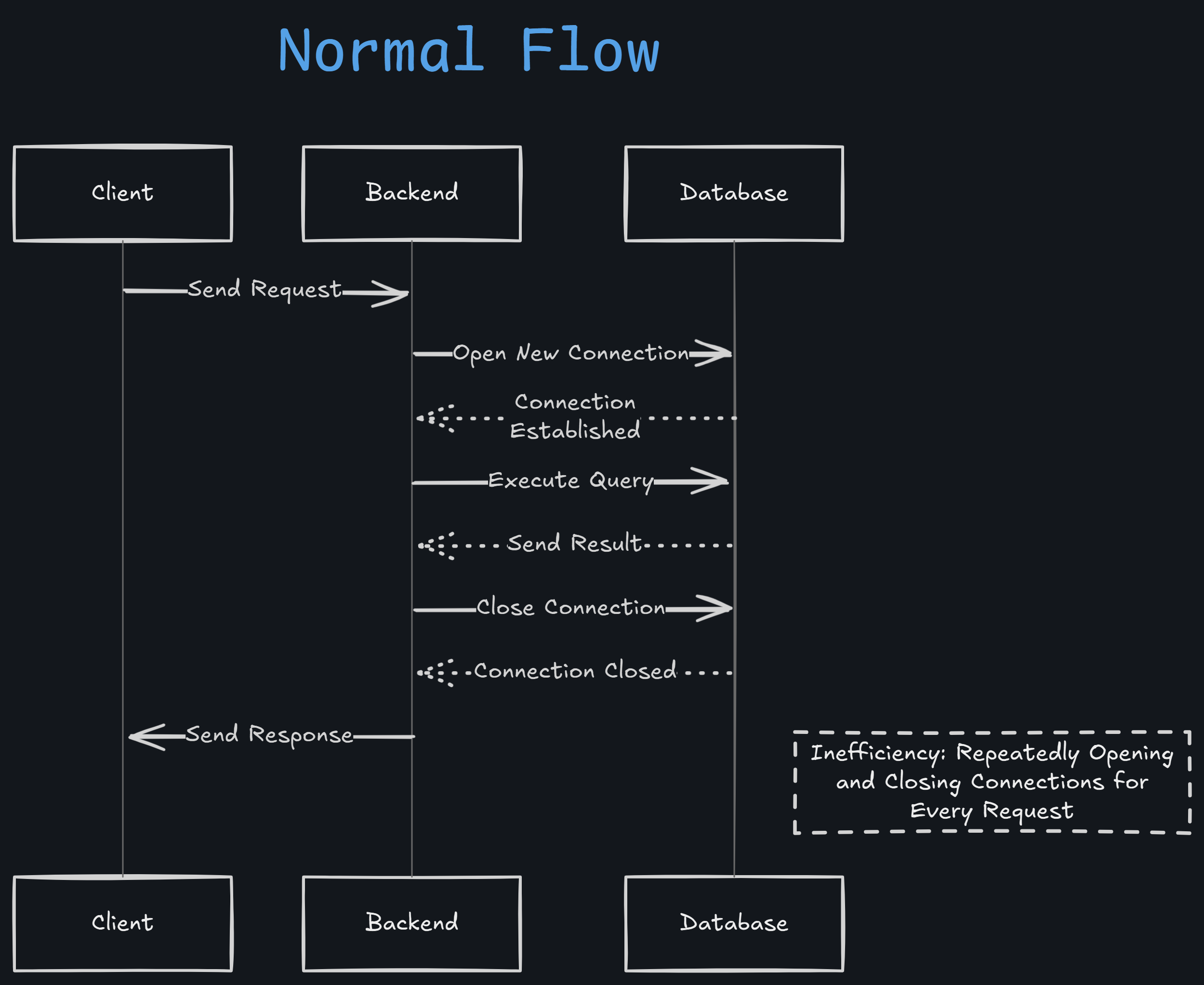
Normally, in an application, database interaction follows this process:
- A request comes to the server.
- The server establishes a connection to the database.
- The request is processed, and the response is returned.
- The connection is closed.
To make a request and get a response, a protocol is required. This is usually TCP (Transmission Control Protocol) or gRPC (gRPC Remote Procedure Calls). Let’s assume TCP is being used. You may already know that TCP has a cost due to the three-way handshake process, which adds latency.
With this native approach, every request opens a new connection to the database and then closes it after processing.
Downsides
- High Resource Consumption: Each request creates a new TCP connection, leading to excessive resource usage.
- Scalability Issues: If site traffic is high, maintaining a separate connection for each user can cause the database to hit its connection limit.
- Increased Costs: Running many connections increases database expenses significantly.
Diagram for Normal Database Interaction
Code for Normal Database Interaction
For demonstration purposes, we’ll use PostgreSQL with Node.js and the pg driver. However, you can use other drivers for different languages:
1. Python
- psycopg2 → Most widely used PostgreSQL adapter
- asyncpg → High-performance async driver for PostgreSQL
-
SQLAlchemy → ORM that uses
psycopg2by default
2. Java
-
PostgreSQL JDBC Driver →
org.postgresql.Driver - Hibernate → ORM that works with PostgreSQL via JDBC
- Spring Data JPA → Uses Hibernate under the hood
3. C# (.NET)
- Npgsql → Official PostgreSQL driver for .NET
-
Entity Framework Core → Uses
Npgsqlfor PostgreSQL
4. PHP
- PDO_PGSQL → PHP Data Object (PDO) driver for PostgreSQL
- pg_connect() → Native PostgreSQL function in PHP
5. Ruby
- pg gem → Default PostgreSQL adapter for Ruby
-
ActiveRecord → Uses
pgfor PostgreSQL in Rails
6. Go
- pgx → High-performance PostgreSQL driver
- database/sql with lib/pq → Go's standard DB driver with PostgreSQL support
1. Install the pg package
npm install pg
2. Create a database connection file (db.js)
const { Client } = require("pg");
// PostgreSQL connection configuration
const client = new Client({
user: "your_username",
host: "localhost",
database: "your_database",
password: "your_password",
port: 5432,
});
// Connect to the database
client.connect()
.then(() => console.log("Connected to PostgreSQL!"))
.catch(err => console.error("Connection error", err.stack));
module.exports = client;
3. Query the Database (index.js)
const client = require("./db");
async function fetchUsers() {
try {
const result = await client.query("SELECT * FROM users");
console.log(result.rows);
} catch (error) {
console.error("Error executing query", error);
} finally {
client.end(); // Close the connection
}
}
fetchUsers();4. Run the script
node index.jsIn this setup, every request establishes a new database connection, processes the query, and then immediately closes the connection. While this may seem straightforward, it introduces significant overhead, consuming unnecessary resources and increasing latency. This approach becomes even more problematic as traffic scales, leading to performance bottlenecks.
To address these inefficiencies, let’s explore connection pooling—a smarter way to manage database connections efficiently.
Connection Pooling
Now, let’s explore connection pooling and how it optimizes database interactions.
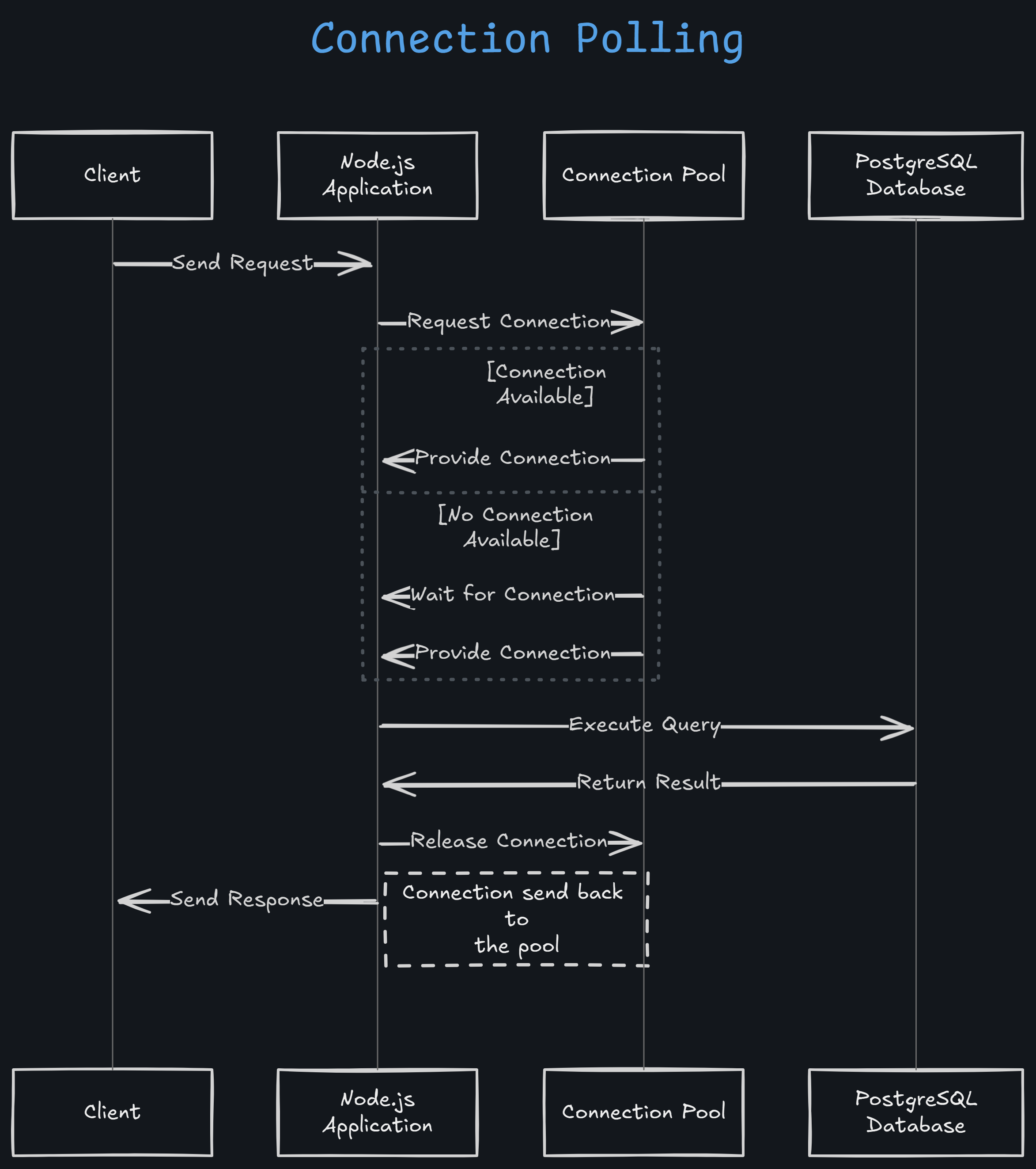
Instead of establishing a new connection for every request, a pool of persistent TCP connections is maintained within the application’s memory, allowing connections to be reused efficiently. This eliminates the overhead of repeatedly opening and closing connections, reducing latency and resource consumption.
For more advanced scenarios, isolated connection pool environments (such as managed database connection pools) are available, but for simplicity, we'll focus on the in-memory approach.
Here’s how it works when a request is made:
- The application retrieves an available connection from the pool.
- The query is executed.
- The connection is returned to the pool, making it ready for reuse.
Benefits of Connection Pooling
- Reduces Latency: No need to establish a fresh TCP connection each time.
- Saves Authentication Time: The database does not need to authenticate every request separately.
- Scalability: The number of connections in the pool can be dynamically increased or decreased based on load.
Diagram for Connection Pooling
Code for Connection Pooling
We will modify the previous code to use connection pooling instead of individual connections.
1. Create a connection pool (db.js)
const { Pool } = require("pg");
// PostgreSQL connection pool configuration
const pool = new Pool({
user: "your_username",
host: "localhost",
database: "your_database",
password: "your_password",
port: 5432,
max: 10, // Maximum number of clients in the pool
idleTimeoutMillis: 30000, // Close idle clients after 30 seconds
connectionTimeoutMillis: 2000, // Return error if connection takes longer than 2 sec
allowExitOnIdle: false, // Prevents process exit if idle clients exist
});
// Event listeners for debugging
pool.on("connect", () => {
console.log("Connected to PostgreSQL!");
});
pool.on("acquire", () => {
console.log("Client acquired from the pool");
});
pool.on("release", () => {
console.log("Client released back to the pool");
});
pool.on("error", (err) => {
console.error("Unexpected error on idle client", err);
process.exit(-1);
});
module.exports = pool;
2. Query the Database (index.js)*
const pool = require("./db");
async function fetchUsers() {
let client;
try {
client = await pool.connect(); // Get a client from the pool
console.log("Connected to database");
const result = await client.query("SELECT * FROM users");
console.log("Users:", result.rows);
} catch (error) {
console.error("Error executing query", error);
} finally {
if (client) client.release(); // Release the client back to the pool
}
}
fetchUsers();3. Run the script
node index.jsThings to Consider When Using Connection Pooling
- Always return connections to the pool after execution. Otherwise, you might run out of connections, leading to application downtime.
- Avoid too few connections in the pool, as this can introduce latency.
- Avoid too many connections, as excessive connections may consume unnecessary resources and slow down the application.
- Set an idle timeout to release connections that remain unused for too long.
- Set a query timeout to ensure connections are not held indefinitely due to slow queries.
Conclusion
Efficient database interaction is crucial for building scalable applications. As we've seen, directly opening and closing connections for every request is inefficient, resource-intensive, and limits scalability.
By implementing connection pooling, we significantly reduce latency, optimize resource usage, and improve overall performance. Instead of repeatedly establishing new connections, a pool of persistent connections is maintained, allowing queries to be executed faster and more efficiently.