Step by Step Guide to Build a Sequential Agent Pipeline using Google Agent Development Kit and Nebius AI Studio🔥
Google’s Agent Development Kit (ADK) is one of the flexible and modular framework to build real-world agents. While it’s optimized for Gemini and the Google ecosystem, it’s actually model-agnostic, deployment-agnostic and plays surprisingly well with other third party tools too.
ADK is designed to make agent development feel more like software development helping you create, deploy and orchestrate agent workflows, whether it's simple tasks or full production pipelines.
If you’ve been exploring how to stitch together tools, models and APIs into production-grade agent workflows, you’ll love how lightweight (and surprisingly fast) this setup is.
In this guide, I'll walk you through setting up a multi-agent system using ADK, integrating tools like Tavily, Exa and Firecrawl. We'll also explore how to leverage powerful LLMs like Meta Llama and Nemotron-Ultra-253B-v1 from Nebius AI Studio to kickstart this agent pipeline.
Let’s dive into it 🚀
I also recorded a full explainer video with working Colab demo, so you can learn everything side-by-side while you follow along:
Tools Overview
Our multi-agent system leverages a suite of powerful tools, llms and platforms:
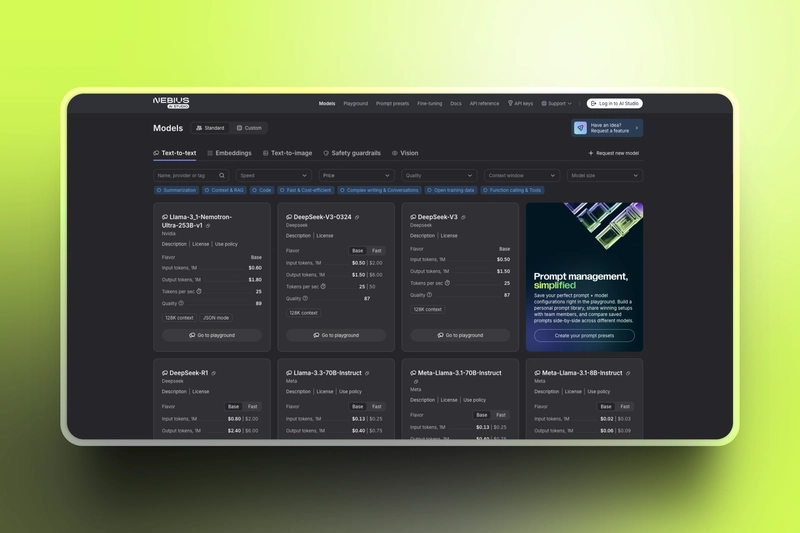
Nebius AI Studio is a powerful inference-as-a-service platform designed for developers and enterprises aiming to deploy and scale AI applications efficiently. It offers a comprehensive suite of open-source models, including LLMs like Llama 3.1 and Nemotron Ultra 253B, as well as text-to-image models such as Flux Schnell and SDXL. With flexible pricing options and scalable infrastructure, Nebius AI Studio enables developers to build, tune and run AI applications efficiently.
Meta's Llama 3.1 is a series of large language models (LLMs) available in various sizes, including 8B, 70B and 405B parameters. These models are optimized for multilingual dialogue and have demonstrated strong performance on industry benchmarks. Llama 3.1 models are instruction-tuned, making them suitable for tasks like text generation, summarization and question-answering. It also has function/tool calling capabilities which is suitable for agentic use case.
You can check the performance benchmarks:
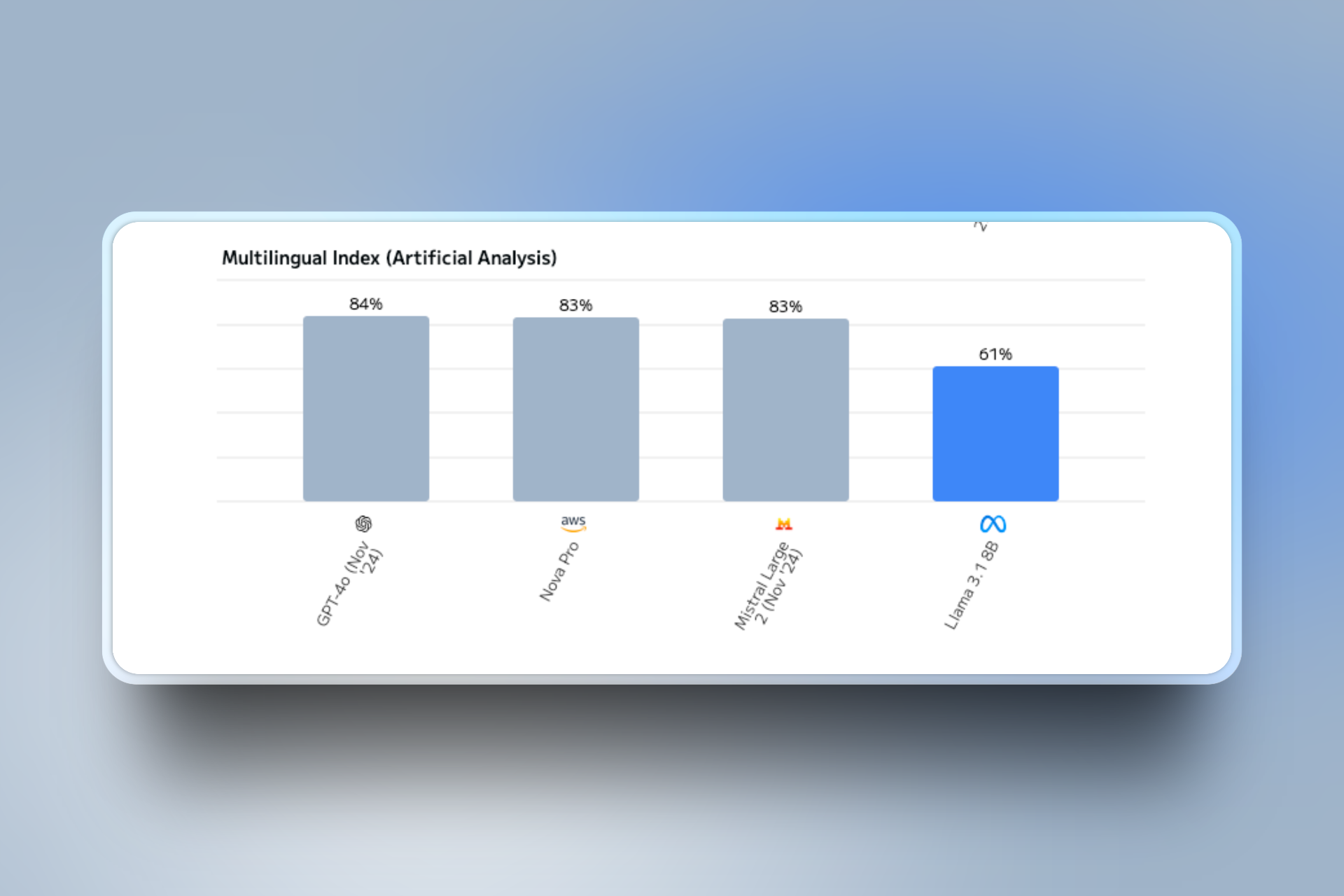
Developed by NVIDIA, Nemotron Ultra 253B v1 is a large language model fine-tuned for advanced reasoning, human chat preferences, and tasks such as RAG and tool calling. Derived from Meta's Llama 3.1 405B, it supports a context length of up to 128K tokens and is optimized for deployment on high-performance hardware. Nemotron Ultra is particularly suited for applications requiring complex reasoning, maths and tool integration.
You can check the evaluation scores and comparison graphs:
Tavily is a search engine optimized for Large Language Models (LLMs), delivering real-time, accurate and unbiased information. It's designed to simplify the integration of dynamic web information into AI-driven solutions by handling the complexities of searching, scraping, filtering and extracting relevant content, all in a single API call. Tavily supports Retrieval-Augmented Generation (RAG) workflows and integrates seamlessly with frameworks like LangChain and LlamaIndex.
Firecrawl is an tool that transforms entire websites into LLM-ready data formats like clean markdown or structured JSON. It crawls accessible subpages without requiring a sitemap and offers features like scraping, crawling, mappin, and data extraction. Firecrawl integrates with various SDKs and frameworks, including Python, Node.js, LangChain and LlamaIndex, facilitating seamless usages into AI workflows.
Exa is a neural search engine tailored for AI applications, utilizing advanced AI language processing to return the most relevant web content. It combines semantic (embedding-based) and keyword search capabilities, allowing for precise information retrieval. Exa's functionalities include finding similar pages, extracting clean HTML content and providing direct answers to queries, making it ideal for enhancing AI agents' search capabilities.
Introduction to Agent-to-Agent (A2A) Protocol and ADK
Google recently announced Agent-to-Agent (A2A) Protocol, It is an open standard that enables seamless communication and collaboration between AI agents, regardless of their underlying frameworks or vendors. By using standardized metadata (Agent Cards) and structured messaging, A2A allows agents to discover each other's capabilities, coordinate tasks and securely exchange information. The protocol supports various data types, including text, JSON and files, and helps orchestrate complex workflows across diverse enterprise platforms.
The Agent Development Kit (ADK) is an open-source framework designed to simplify the creation and deployment of AI agents and multi-agent systems. ADK provides a modular architecture, giving developers fine-grained control over agent behavior and orchestration. It supports integration with a variety of language models, including Google’s Gemini through Vertex AI and offers a rich set of tools and connectors for easy system integration.
Together, A2A and ADK empower developers to build robust, interoperable and scalable AI agent ecosystems capable of handling complex collaborations across platforms.
Our Sequential Agent Workflow
Our app has a SequentialAgent workflow, powered by Nebius-hosted LLMs like meta-llama/Meta-Llama-3.1-8B-Instruct and nvidia/Llama-3_1-Nemotron-Ultra-253B-v1 to analyze AI trends, where each agent performs a specific task in a defined sequence.
Our ADK sequential agent app will execute tasks in this order👇

ExaAgent: Fetches the latest AI news and advancements from Twitter/X using Exa.
TavilyAgent: Retrieves AI benchmarks, statistics and analysis from artificialanalysis.ai using Tavily.
SummaryAgent: Combines and summarizes the findings from ExaAgent and TavilyAgent.
FirecrawlAgent: Scrapes content from the Nebius AI Studio homepage using Firecrawl.
AnalysisAgent: Analyzes all gathered information, including Nebius AI Studio offerings, to identify trends and recommend relevant AI models.
Our ADK sequential agent app (AI Trend Analyzer) workflow will be like this👇
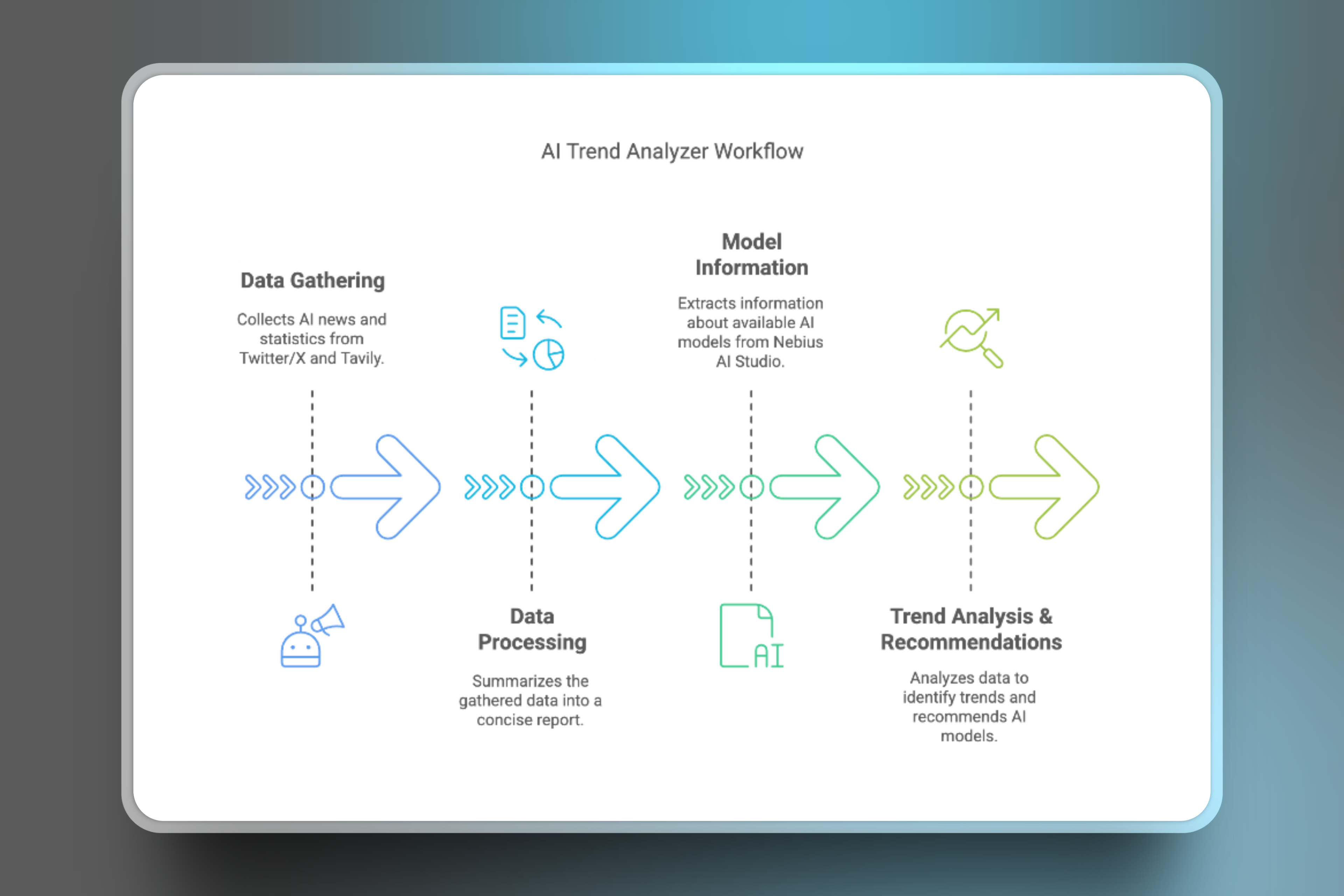
This modular approach ensures a focused and maintainable system for comprehensive AI trend analysis.
Now, let’s move on to the code implementation steps. 🔥
Full Implementation of Multi-Agent App
I’ve implemented the demo using both Google Colab and VS Code, but for this tutorial, I’ll walk you through the Colab setup — it’s much simpler and quicker to get started.
Here’s how you can install all the necessary packages and SDKs, including the Google Agent Development Kit (ADK), to run your app smoothly in Google Colab:
!pip install -q google-adk litellm python-dotenv exa-py tavily-python firecrawl-pyYou might be wondering why we need to install litellm along with the other tools. That's because, even though the Google Agent Development Kit heavily relies on Vertex AI, Gemini and the Google ecosystem, it also allows using Cloud, Open & Proprietary LLMs through LiteLLM.
LiteLLM acts as a translation layer, providing a standardized, OpenAI-compatible interface to over 100 LLMs from various providers, including OpenAI, Anthropic, Nebius AI Studio, and more. This integration allows developers to access a diverse set of models without being confined to a single provider.
Before going to next step, please create a account on all the tools mentioned above and get your API keys.Step 1: Importing Required Libraries
# Import necessary libraries for Google ADK, LLMs, and data processing
from google.adk.models.lite_llm import LiteLlm
from google.adk.agents.llm_agent import LlmAgent
from google.adk.agents.sequential_agent import SequentialAgent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
# Import libraries for data retrieval and web scraping
from exa_py import Exa
from tavily import TavilyClient
from firecrawl import FirecrawlApp
# Import standard libraries for system operations and time handling
import os
from datetime import datetime, timedelta
from google.genai import typesStep 2: Setting Up API Keys
os.environ["NEBIUS_API_BASE"] = "https://api.studio.nebius.ai/v1"
os.environ["NEBIUS_API_KEY"] = "your-api-key"
os.environ["EXA_API_KEY"] = "your-api-key"
os.environ["TAVILY_API_KEY"] = "your-api-key"
os.environ["FIRECRAWL_API_KEY"] = "your-api-key"Step 3: LLM Model Setup Using Nebius AI Studio with LiteLLM
nebius_model = LiteLlm(
model="openai/meta-llama/Meta-Llama-3.1-8B-Instruct",
api_base=os.getenv("NEBIUS_API_BASE"),
api_key=os.getenv("NEBIUS_API_KEY")
)Now that the initial setup is complete, it’s time to define the tools our agents will use. We’ll create three tools:
A tool to perform web searches on X (formerly Twitter),
A tool to search using a single URL,
And a third tool to scrape content from the Nebius AI website.
Step 4: Tool Definitions (Exa + Tavily + Firecrawl)
# Tool 1: Define a function to search for AI-related news using Exa on X
def exa_search_ai(_: str) -> dict:
results = Exa(api_key=os.getenv("EXA_API_KEY")).search_and_contents(
query="Latest AI news OR new LLM models OR AI/Agents advancements",
include_domains=["twitter.com", "x.com"],
num_results=10,
text=True,
type="auto",
highlights={"highlights_per_url": 2, "num_sentences": 3},
start_published_date=(datetime.now() - timedelta(days=30)).isoformat()
)
return {"type": "exa", "results": [r.__dict__ for r in results.results]}
# Tool 2: Define a function to search artificialanalysis.ai using Tavily
def tavily_search_ai_analysis(_: str) -> dict:
client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
response = client.search(
query="AI benchmarks OR AI/LLM statistics OR AI providers analysis",
search_depth="advanced",
time_range="week",
include_domains=["artificialanalysis.ai"]
)
return {"type": "tavily", "results": response.get("results", [])}
# Tool 3: Define a function to Scrape content of Nebius AI using Firecrawl
def firecrawl_scrape_nebius(_: str) -> dict:
firecrawl = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
try:
scrape_result = firecrawl.scrape_url(
url="https://studio.nebius.com/",
formats=["markdown"],
only_main_content=True
)
if scrape_result.success:
return {
"type": "firecrawl",
"markdown": scrape_result.markdown # ✅ directly access
}
else:
return {
"type": "firecrawl",
"error": "Scraping failed."
}
except Exception as e:
return {
"type": "firecrawl",
"error": str(e)
}Step 5: Agent Definitions
Now that the tools are set up, it’s time to define our AI agents. We'll create five agents, three will use specific tools to perform web searches and scraping tasks, while two agents will handle summarization and deeper analysis of the results.
Agent 1: Exa Agent — Fetch Latest AI News from X
This agent uses exa-search-ai tool to gather the latest updates about AI, LLM advancements and tech news from platforms like X (formerly Twitter):
# Agent 1: Define the Exa agent to fetch latest AI updates from X
exa_agent = LlmAgent(
name="ExaAgent",
model=nebius_model,
description="Fetches latest AI news, LLMs, and advancements using Exa.",
instruction="""
Use the exa_search_ai tool to fetch the latest information about AI, new LLMs, and advancements in the field from Twitter and X.
Prefix your response with "**🔥ExaAgent:**"
""",
tools=[exa_search_ai],
output_key="exa_news"
)Agent 2: Tavily Agent — Fetch AI Benchmarks and Stats
This agent uses tavily_search_ai_analysis tool to fetch AI-related benchmarks, performance statistics, and industry analyses from https://artificialanalysis.ai/:
# Agent 2: Define the Tavily agent to fetch AI benchmarks and related infos
tavily_agent = LlmAgent(
name="TavilyAgent",
model=nebius_model,
description="Fetches AI benchmarks, statistics, and analysis using Tavily.",
instruction="""
Use the tavily_search_ai_analysis tool to retrieve benchmarks, statistics, llm providers and relevant analysis on AI.
Prefix your response with "**🐳TavilyAgent:**"
""",
tools=[tavily_search_ai_analysis],
output_key="tavily_news"
)Agent 3: Summary Agent — Combine and Format Search Results
This agent summarizes and formats the outputs from the Exa and Tavily agents into a developer-friendly, markdown-rich summary:
# Agent 3: Define the Summary agent to combine and format results from Exa and Tavily Agent
summary_agent = LlmAgent(
name="SummaryAgent",
model=nebius_model,
description="Summarizes and formats Exa and Tavily results.",
instruction="""
You are a summarizer and formatter.
- Combine the information from 'exa_results' and 'tavily_results'.
- Use markdown, bullet points, emojis (🚀, 📊, 📈).
- Prefix with "**🍥SummaryAgent:**"
""",
tools=[],
output_key="final_summary"
)Agent 4: Firecrawl Agent — Scrape Nebius AI Studio Website
This agent uses firecrawl_scrape_nebius tool to scrape structured content from the Nebius AI Studio homepage, preparing it for analysis:
# Agent 4: Define the Firecrawl scrapper agent to scrape content of Nebius AI Studio
firecrawl_agent = LlmAgent(
name="FirecrawlAgent",
model=nebius_model,
description="Scrapes Nebius Studio homepage using Firecrawl.",
instruction="""
Use the firecrawl_scrape_nebius tool to fetch markdown content from Nebius Studio website in proper format.
Prefix your response with "**🔥FirecrawlAgent:**"
""",
tools=[firecrawl_scrape_nebius],
output_key="firecrawl_content"
)Agent 5: Analysis Agent — Analyze Summary and Scraped Data
This agent performs an in-depth analysis of the summarized results and the scraped Nebius content. It identifies key AI trends, matches LLM features to Nebius offerings and presents insights using markdown tables.
In the previous steps, all agents were using the meta-llama/Meta-Llama-3.1-8B-Instruct model to perform their assigned tasks. However, for the final analysis, we require a more powerful LLM to handle deeper insights and cross-referencing across multiple data sources.
For this reason, we switch to nvidia/Llama-3_1-Nemotron-Ultra-253B-v1, one of the most capable and advanced models available for complex analysis tasks.
# Agent 5: Define the Analysis agent to analyze the summary and provide insights and also consider Nebius Scrapped data
analysis_agent = LlmAgent(
name="AnalysisAgent",
model=LiteLlm(
model="openai/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1",
api_base=os.getenv("NEBIUS_API_BASE"),
api_key=os.getenv("NEBIUS_API_KEY")
),
instruction="""
You are an AI analyst specializing in the latest AI trends and Large Language Models (LLMs).
- Analyze the 'final_summary', combining it with your knowledge of AI advancements and the information extracted from 'exa_results' and 'tavily_results'.
- Identify key trends, growth areas, and notable statistics related to AI and LLMs.
- Carefully examine the 'firecrawl_content', which contain data from Nebius AI Studio. This file provides details about available models on Nebius, including their names, pricing, token limits, and availability.
- Instead of focusing solely on model names, analyze the functional capabilities and intended use cases of LLMs mentioned in the 'final_summary'.
- Cross-reference the LLMs' functionalities with the Nebius AI Studio offerings in 'firecrawl_content', prioritizing models with similar features such as context window size, training data, or specialized capabilities.
- Utilize any available metadata in 'firecrawl_content', such as model descriptions, tags, or categories, for more accurate matching.
- If a relevant LLM is found on Nebius, provide a specific recommendation to the user, highlighting its features, pricing, token limits, and potential benefits based on the context from the 'final_summary'.
- If no exact match is found, suggest alternative Nebius models with the closest functional alignment to the desired capabilities.
- If a close match is found, suggest the possibility of fine-tuning the Nebius model to better align with the specific requirements.
- Present your analysis with clear and concise language, supported by quantifiable data and insights.
- Utilize markdown tables for statistics, as demonstrated below:
| Metric | Value |
|---|---|
| Growth Rate | 25% |
| Market Size | \$100 Billion |
- Always prefix your response with "**🔍AnalysisAgent:**" for clear identification.
""",
description="Analyzes the summary and presents insights and statistics.",
output_key="analysis_results"
)Step 6: Pipeline & Execution - Host Agent with Google ADK
With all individual agents and tools configured, the next phase involves orchestrating them into a cohesive workflow. Google's Agent Development Kit (ADK) facilitates this through the SequentialAgent, which ensures that each agent executes in a predefined order, passing outputs seamlessly to subsequent agents.
Defining the Orchestrator ( SequentialAgent ) - The SequentialAgent serves as the orchestrator, managing the execution flow of sub-agents in a deterministic sequence. This approach is ideal for structured AI workflows where the output of one agent informs the input of the next. In our setup, the pipeline comprises five agents.
Setting Up the Execution Environment with Runner - To execute the defined pipeline, we utilize the Runner class in conjunction with an in-memory session service. This setup manages the session state and facilitates the execution of the agent sequence.
Here's how to configure SequentialAgent, session and runner:
# This agent orchestrates the pipeline by running the sub_agents in order.
pipeline = SequentialAgent(
name="AIPipelineAgent",
sub_agents=[exa_agent, tavily_agent, summary_agent, firecrawl_agent, analysis_agent]
)
# Set up session and runner for the pipeline
APP_NAME = "ai_analysis_pipeline"
USER_ID = "colab_user"
SESSION_ID = "ai_analysis_session"
session_service = InMemorySessionService()
session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
runner = Runner(agent=pipeline, app_name=APP_NAME, session_service=session_service)This configuration prepares the environment for executing the AI analysis pipeline, ensuring that each agent operates within the defined session context.
Step 7: Run the AI Trend Analysis Agent App
With all agents and tools configured and orchestrated using Google's Agent Development Kit (ADK), it's time to run the AI Trend Analysis pipeline. This step involves initiating the sequence of agents to perform tasks such as fetching AI news, analyzing benchmarks, summarizing insights and scraping relevant content.
We begin by defining a function that sends a user prompt to the orchestrated agent pipeline and processes the resulting events:
# Define the main function to run the AI analysis
def run_ai_analysis():
content = types.Content(role="user", parts=[types.Part(text="Start the AI analysis")])
events = runner.run(user_id=USER_ID, session_id=SESSION_ID, new_message=content)
for event in events:
if event.is_final_response():
print("📢 AI News Analysis and Insights:\n")
print(event.content.parts[0].text)
# Execute the AI analysis sequence
run_ai_analysis()Upon execution, the pipeline performs the following sequence:
ExaAgent: Retrieves the latest AI news and updates from X (formerly Twitter).
TavilyAgent: Gathers AI benchmarks, statistics and related analyses.
SummaryAgent: Consolidates and formats the information from the previous agents.
FirecrawlAgent: Scrapes content from the Nebius AI Studio homepage.
AnalysisAgent: Analyzes the summarized data and scraped content to provide actionable insights.
The final output presents a comprehensive overview of current AI trends, benchmarks, and model analyses, aiding in informed decision-making and strategy development, here’s a part of response:
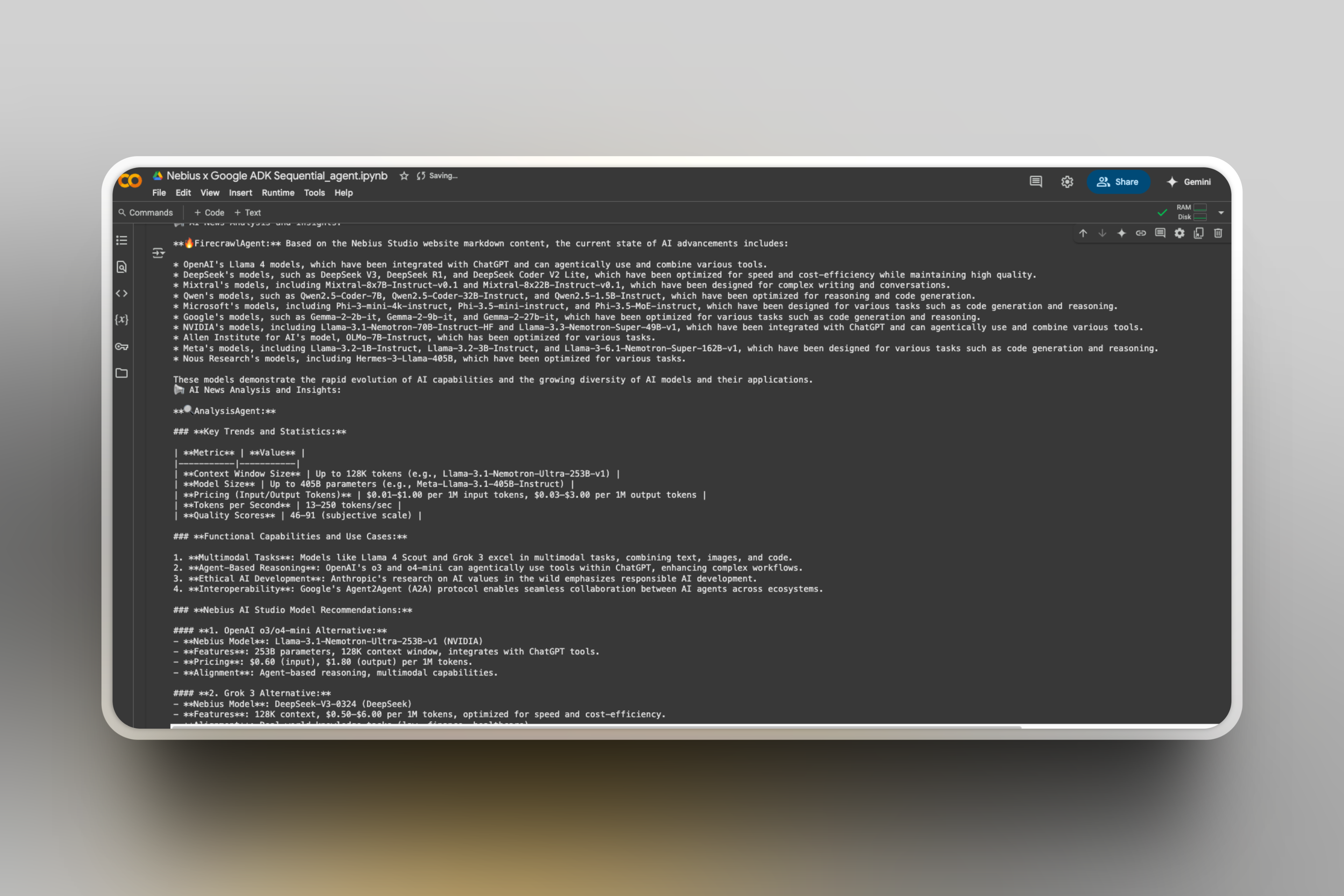
Wow🚀, now your ADK agent app is ready.
Before we wrap up, it's worth highlighting that Google's Agent Development Kit (ADK) offers more than just command-line tools. By running adk web, you can access a comprehensive Web UI that enhances the development experience:
Visual Flowcharts: Understand agent workflows through intuitive diagrams.
Interactive Debugging: Inspect agent states, inputs, and outputs in real-time.
Evaluation Tools: Create and manage evaluation sets to test agent performance.
Deployment Options: Easily deploy agents to platforms like Google Cloud Run or Vertex AI Agent Engine.
This integrated interface streamlines the process of building, testing, and deploying AI agents, making ADK a powerful tool for developers.
Here's the demo of web UI while executing the simple ADK agent app I built earlier:
Conclusion
In this tutorial, we've explored how to build a multi-agent AI analysis pipeline using Google's Agent Development Kit (ADK). By integrating tools like Exa, Tavily, Firecrawl, and Nebius AI Studio, we've demonstrated how to orchestrate agents for tasks such as real-time web search, content scraping, summarization and in-depth analysis.
Leveraging ADK's capabilities, including its Web UI for visualization and evaluation, developers can craft scalable, modular, and interactive AI agents tailored to various use cases. This framework not only streamlines the process of gathering and analyzing AI-related information but also showcases the practical application of orchestrated agents in real-world scenarios.
Whether you're exploring AI trends, automating research workflows or developing intelligent applications, this setup offers a robust foundation to build upon.
Ready to elevate your AI agent game? Dive into ADK and start building today.
🧰 Additional Resources
ADK Agent Demos
Full explainer video is available on YouTube
This repository contains various agent demos built with Google's ADK (Agent Development Kit), showcasing different patterns and capabilities for building AI agents.
LLM Integration
All demos in this repository are powered by Nebius AI using open-source LLMs:
- Meta-Llama-3.1-8B-Instruct - Used in most agent implementations
- Llama-3_1-Nemotron-Ultra-253B - Used for advanced analysis in the Analyzer Agent
These models are integrated via LiteLLM, which ADK supports for connecting to various model providers.
Agent Demos
Agent Pattern Description Details Analyzer Agent 5-agent sequential pipeline AI trends analysis with multiple data sources README Email Agent Single agent with tool Email integration with Resend API README Sequential Agent 3-agent sequential pipeline News aggregator combining IPL and AI news README Multi-Tool Search Root agent with delegation Modular search with agent delegation README For detailed information about each agent, please refer to the individual READMEs in…
If you'd like to explore more real-world examples of agents built with Google's ADK, check out my ADK-Agent-Examples repository. This features multiple ADK agent demos powered by Meta-Llama-3.1-8B-Instruct and Llama-3_1-Nemotron-Ultra-253B models via Nebius AI and LiteLLM integration.
You’ll find implementations covering:
Sequential Agent Pipelines (multi-agent workflows),
Tool Integration (using APIs like Resend),
Agent Delegation (root agent delegating tasks),
Multi-Model Usage (choosing models based on tasks),
and Specialized Agents (for search, summarization and analysis).
Official ADK sample repo of Google is also available here


Dive into these repos to learn practical ADK patterns and build your own scalable multi-agent systems, contributions are welcome to the repository🙌
Thankyou for reading! If you found this article useful, share it with your peers and community.
If You ❤️ My Content! Connect Me on Twitter
Check SaaS Tools I Use 👉🏼Access here!
I am open to collaborating on Blog Articles and Guest Posts🫱🏼🫲🏼 📅Contact Here


