This article will introduce how to quickly import csv or txt files larger than 1g into the database.
Here, we prepared a CSV file with 10 million rows x 30 columns x 4GB. At first, I tried to import it with Navicat.
The first problem I encountered was that the encoding format was unknown, which led to many attempts to find the correct encoding.
The second problem is that Navicat reads and writes one by one. Although this does not take up memory, the speed is very slow.
The third problem is that halfway through the import, an error was reported because the field length was not enough! ! ! I had to reset the field length and import from 0 again. . . What's worse is that after setting one field, another error was reported. . .
Now, we use the DiLu Converter Import tool to solve these problems one by one.
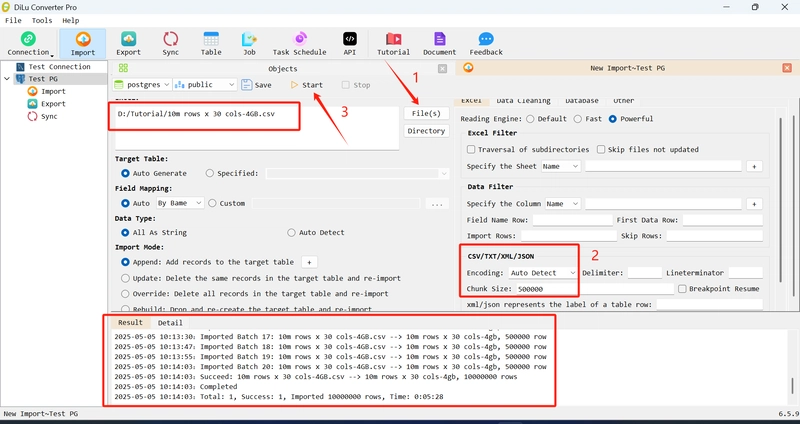
Begin Import
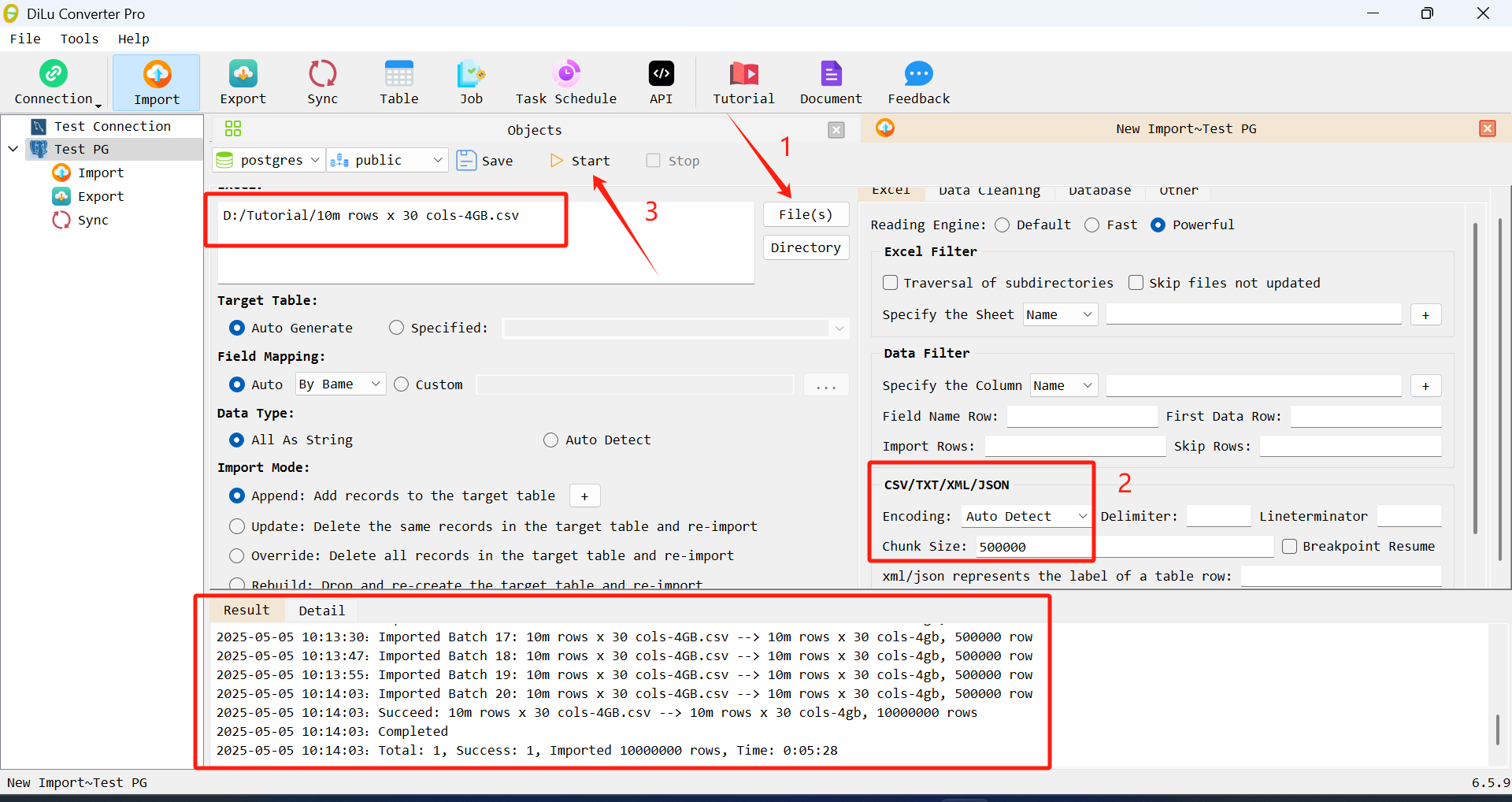
Encoding: It can be automatically identified by default (for files with unknown encoding). If the encoding format of the file is known, you can select or enter its encoding format to speed up the parsing speed.
Chunk Size: You can set the number of rows to import at a time according to the available memory of your computer. My computer has a total of 16G memory, about 9G is available, and 500,000 is set in a batch. Here, you must set the size according to the available memory. If the setting is too large, the memory may overflow, and if the setting is too small, it will not speed up.
And The just click start
You can see that it takes about 20 seconds to import a batch of 500,000 rows, and the memory usage is less than 1G
Finally, it took about 5 minutes to import this csv file of 10 million rows x 30 columns x 4GB, and the maximum memory usage was about 1G. Because the tool imports files in batches according to batch size, no matter it is 1 file or hundreds or thousands of files, no matter a single file is 1G or 100G, as long as the batch size is set reasonably, it can be imported quickly, stably and without consuming memory.