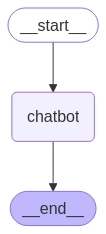
A construção de aplicações com Large Language Models (LLMs) evoluiu rapidamente. Frameworks como LangChain nos deram as ferramentas para conectar LLMs com fontes externas, memória, e agentes capazes de tomar decisões. Mas à medida que a complexidade dos fluxos aumenta, surge um desafio comum: como orquestrar o comportamento dos agentes de forma flexível, controlável e com lógica mais rica que simples pipelines lineares?
É aqui que entra o LangGraph.
O que é o LangGraph?
O LangGraph é uma extensão do LangChain que permite construir fluxos de execução orientados a grafos para LLMs e agentes. Em vez de seguir uma sequência fixa de passos (como num pipeline tradicional), você define nós (nodes) e arestas (edges) que representam o comportamento dinâmico do sistema.
Com ele, é possível criar aplicações onde o fluxo depende do estado atual da execução, decisões do agente ou resultados intermediários algo essencial para sistemas multiagentes, diálogos complexos, rotas condicionais e muito mais.
Por que usar LangGraph?
Algumas razões para considerar o LangGraph:
- Controle total sobre o fluxo de execução, incluindo loops, decisões condicionais e bifurcações.
- Escalabilidade para agentes mais complexos, sem se perder em estruturas monolíticas.
- Modelagem de estado simples e transparente, facilitando o debug e a manutenção.
- Composição modular, onde cada nó do grafo pode representar um agente, ferramenta ou processo.
Conceitos-chave
Antes de mostrar um exemplo, vale entender os conceitos básicos:
- Node (nó): uma função ou agente que processa o estado atual.
- Edge (aresta): uma transição entre nós, baseada em uma regra.
- State (estado): dados compartilhados que são passados entre os nós.
- Graph (grafo): a definição do fluxo completo da aplicação.
Mão na Massa
Vamos começar de exemplos mais simples e evoluir para algo mais interessante.
Requisitos:
- Python >= 3.10
- uv
01 - Simples ChatBot
Vamos criar um chatbot interativo que responde em tempo real usando a biblioteca LangGraph, um wrapper para fluxos de conversa com LLMs, e LiteLLM, que pode ser usado com modelos da OpenAI ou vários outros desde LLM até SLM (neste caso, gpt-4.1-nano).
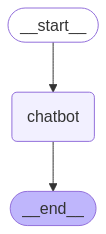
A imagem acima mostra o fluxo. Apesar de ser bem simples, ele começa, passa pelo chat e termina. É claro que podemos ter fluxos mais complexos, porém, para este primeiro exemplo, optei por um mais simples.
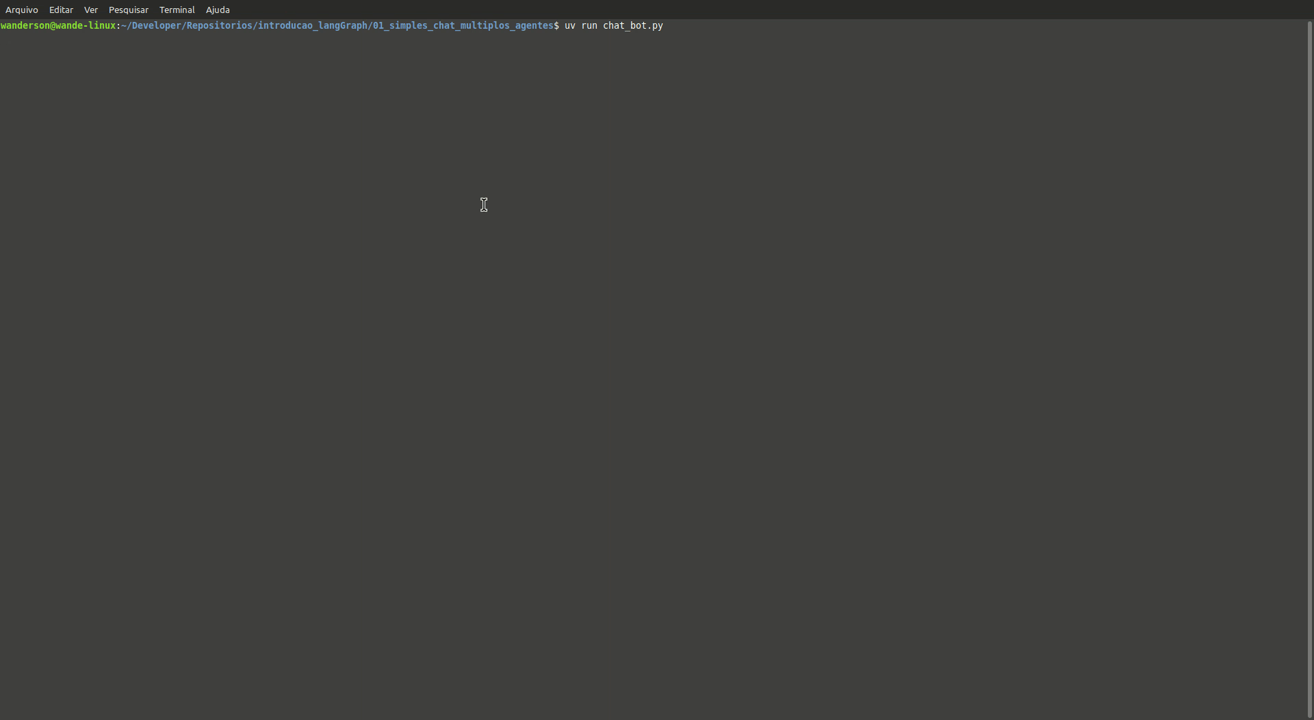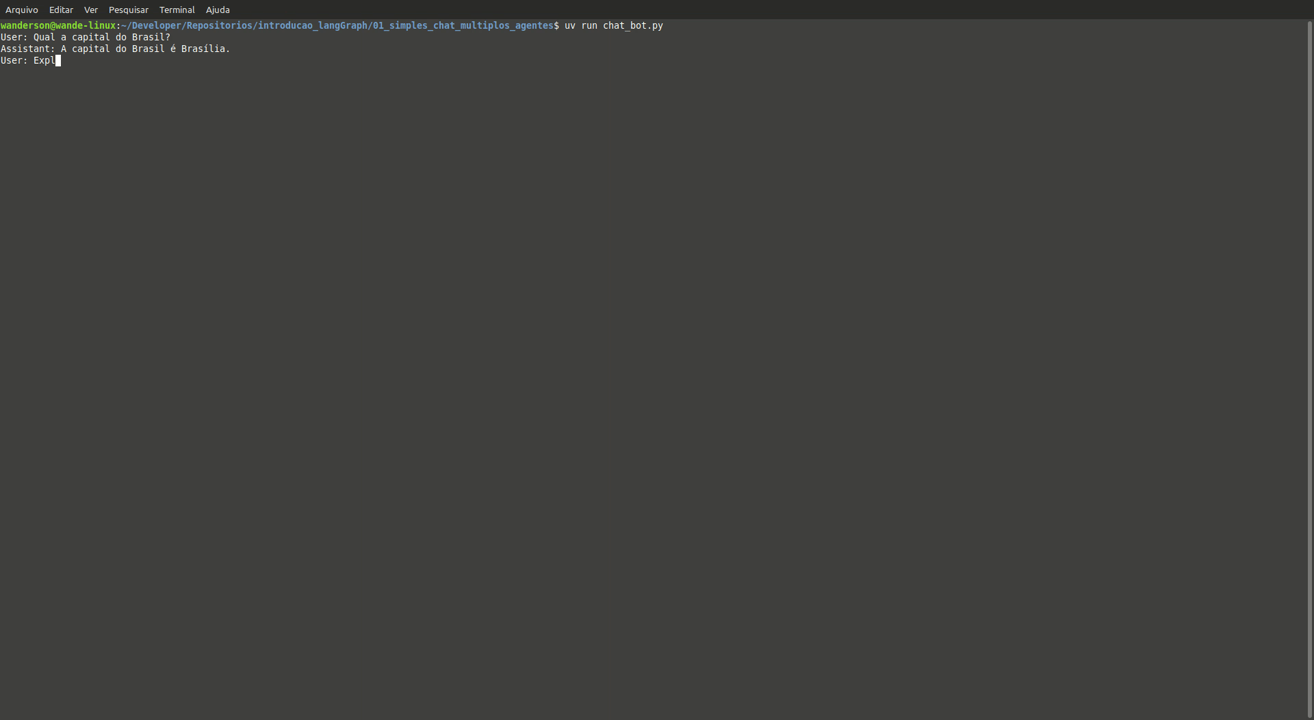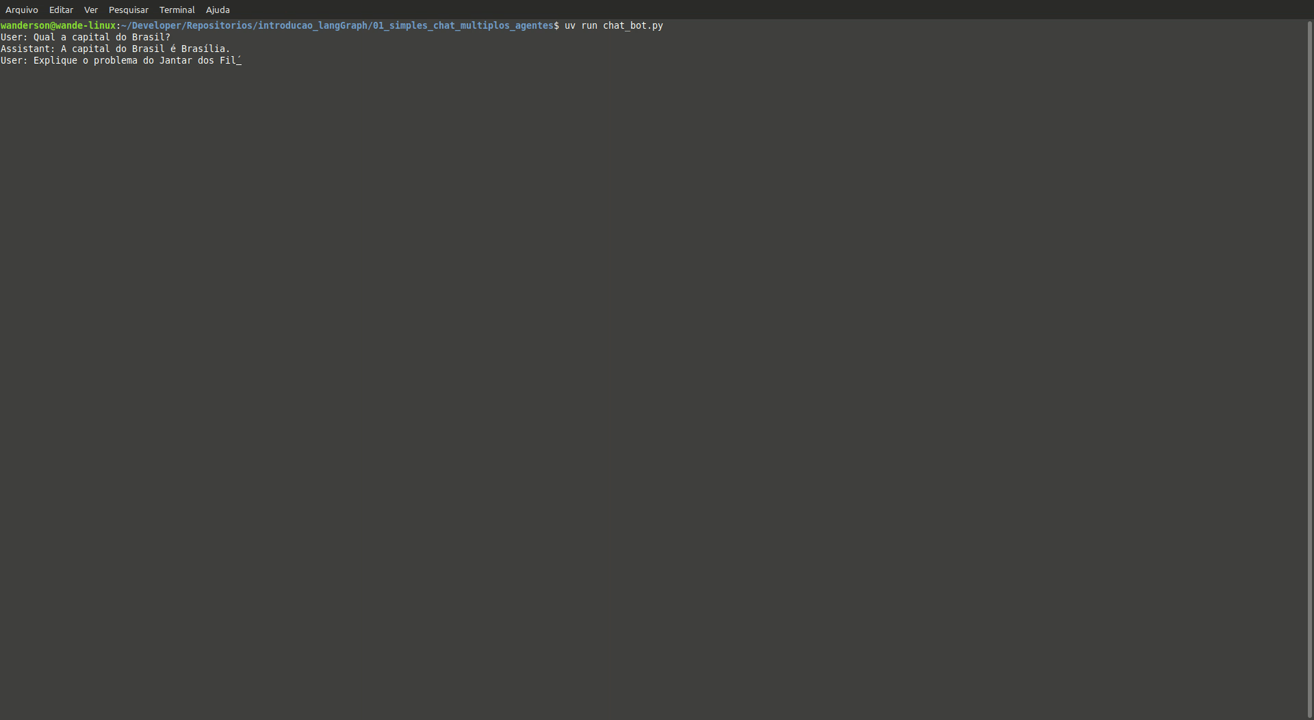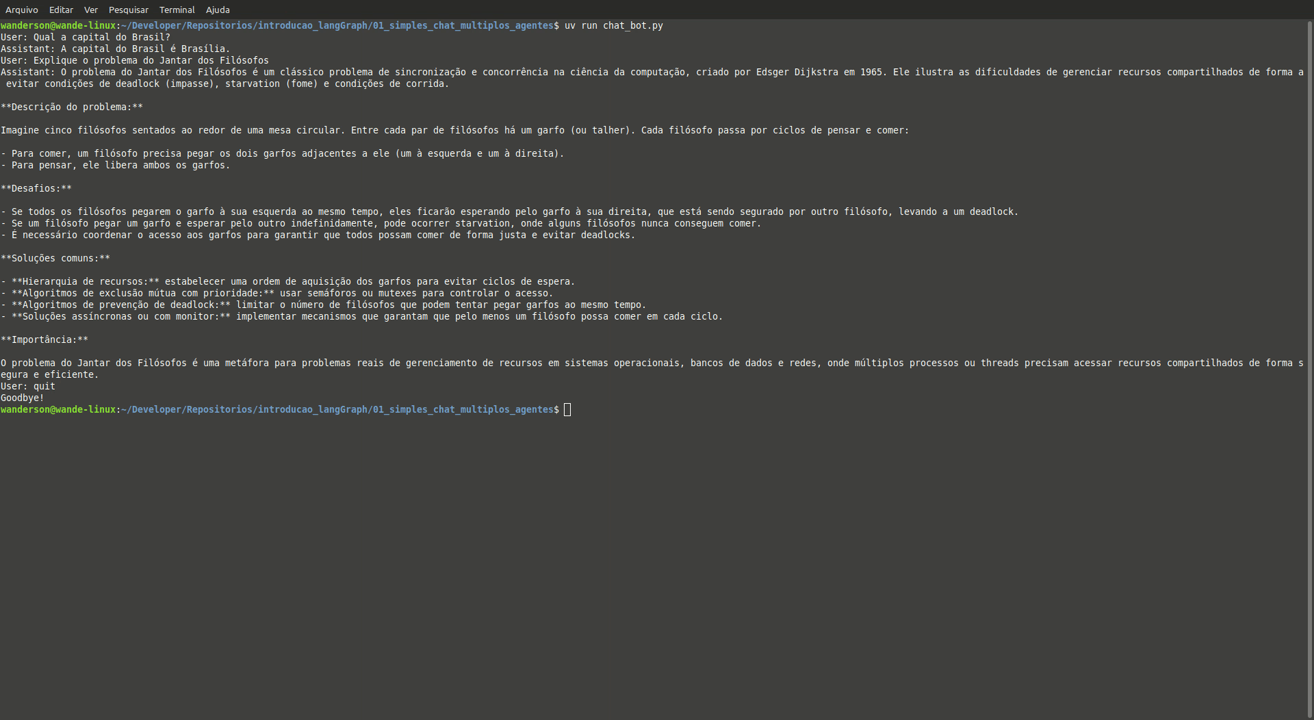
Ao executar o uv run chat_bot.py o usuário poderá em linguagem natural interagir com o chat que vai executar o fluxo e usar a LLM da OpenAI para retornar.
Código completo:
import os
from dotenv import load_dotenv
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_litellm import ChatLiteLLM
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
llm = ChatLiteLLM(model="gpt-4.1-nano", temperature=0.1)
class State(TypedDict):
messages: Annotated[list, add_messages]
def send(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", send)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
breaka - Importações e configuração de ambiente
import os
from dotenv import load_dotenv
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_litellm import ChatLiteLLM- Carrega variáveis de ambiente do .env.
- Usa ChatLiteLLM vamos usar com um SDK para acessar vários LLMs.
- Usa LangGraph, que permite construir fluxos de estados conversacionais com LLMs.
- add_messages é um utilitário do LangGraph que facilita o histórico de mensagens.
StateGraph
- É a classe principal usada para construir grafos de estado no LangGraph.
- Permite definir nós (funções que manipulam o estado), e como os estados/nós se conectam.
- É uma forma estruturada de montar pipelines de execução com LLMs, mantendo o controle do fluxo de dados (estado).
Exemplo de uso:
graph_builder = StateGraph(State)Aqui você está dizendo: quero construir um grafo de estados baseado no tipo de estado State.
START
- Representa o ponto de entrada do grafo — onde a execução começa.
- Ao adicionar uma aresta partindo de START, você define qual será o primeiro nó a ser executado.
Exemplo:
graph_builder.add_edge(START, "chatbot")Isso diz: “comece no nó chatbot”.
END
- Representa o ponto final do grafo — onde a execução termina.
- Você adiciona uma aresta para END a partir do último nó do seu fluxo.
Exemplo:
graph_builder.add_edge("chatbot", END)Isso significa: depois de executar chatbot, finalize o grafo.
b - Carrega a chave da API e configura o modelo
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
llm = ChatLiteLLM(model="gpt-4.1-nano", temperature=0.1)- Carrega a chave da API a partir do arquivo .env.
- Configura o modelo LLM para ser usado nas respostas.
c - Define o estado da conversa
class State(TypedDict):
messages: Annotated[list, add_messages]- O estado é um dicionário tipado com uma chave messages, que é uma lista anotada com add_messages.
- Isso permite que LangGraph trate corretamente o histórico da conversa.
d - Função que envia mensagens para o modelo
def send(state: State):
return {"messages": [llm.invoke(state["messages"])]}- Recebe o histórico da conversa e chama o modelo com ele (llm.invoke(...)).
- Retorna uma nova mensagem (resposta do assistente) dentro da chave messages.
e - Constrói o fluxo do grafo conversacional
graph_builder = StateGraph(State)
graph_builder.add_node("chatbot", send)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
graph = graph_builder.compile()Cria um grafo de estados:
- Começa em START, vai para o nó chatbot (função send) e termina em END.
- Um fluxo simples de entrada → resposta.
02 - Avaliador de Redação
Nesse outro exemplo vamos criar agentes IA para avaliar redações. Um coisa muito legal no LangGraph é ter fluxos condicionais, onde podemos criar condições e navegar pelas arestas. Este código implementa um sistema automatizado de avaliação de redações usando IA (LLMs) e um fluxo de trabalho baseado em grafo com a biblioteca LangGraph.
a - Objetivo Geral
Avaliar automaticamente uma redação com base em quatro critérios:
- Relevância com o tema
- Gramática
- Estrutura do texto
- Profundidade da análise
Cada critério recebe uma pontuação de 0 a 1, e uma pontuação final ponderada é calculada.
- Relevância do Conteúdo: Avalia quão bem a redação aborda o tema proposto
- Verificação Gramatical: Avalia o uso da linguagem e a correção gramatical da redação
- Análise da Estrutura: Examina a organização e o fluxo de ideias na redação
- Profundidade de Análise: Mede o nível de pensamento crítico e insight apresentado
- Cada etapa é executada condicionalmente com base nas pontuações das etapas anteriores, permitindo o término antecipado de redações de baixa qualidade. A pontuação final é uma média ponderada de todas as pontuações dos componentes individuais.
b - Funções de Avaliação
Cada função chama o LLM com um prompt específico e extrai a nota da resposta:
- verificar_relevancia(state): Avalia o quanto a redação está relacionada ao tema.
- verificar_gramatica(state): Avalia a correção gramatical.
- analizar_estrutura(state): Avalia a estrutura do texto.
- avaliar_profundidade(state): Avalia a profundidade da análise e argumentação.
- extrair_pontuacao(content): Função auxiliar para extrair o número da resposta do LLM.
c - Cálculo da Nota Final
calcular_pontuacao_final(state): Combina as notas com pesos:
- Relevância: 30%
- Gramática: 20%
- Estrutura: 20%
- Profundidade: 30%
d - Fluxo com LangGraph
- Um grafo de execução (workflow) é construído com as etapas acima.
- Fluxo condicional: Se uma nota for muito baixa, pode pular avaliações seguintes. Ex: Se a relevância ≤ 0.5, vai direto calcular a nota final.
Código completo:
import os
from dotenv import load_dotenv
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langchain_litellm import ChatLiteLLM
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
import re
class State(TypedDict):
""" Representa o estado do processo de avaliação da redação """
redacao: str
pontuacao_relevancia: float
pontuacao_gramatica: float
pontuacao_estrutura: float
pontuacao_profundidade: float
pontuacao_final: float
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
llm = ChatLiteLLM(model="gpt-4.1-nano", temperature=0.1)
def extrair_pontuacao(content: str) -> float:
"""Extrai a pontuação numérica da resposta do LLM."""
match = re.search(r'Pontuação:\s*(\d+(\.\d+)?)', content)
if match:
return float(match.group(1))
raise ValueError(f"Não foi possível extrair a pontuação de: {content}")
def verificar_relevancia(state: State) -> State:
"""Verifica a relevância da redação."""
messages = [
HumanMessage(
content= "Analise a relevância da seguinte redação em relação ao tema dado, prezando pela excelência da Língua Portuguesa. "
"Forneça uma pontuação de relevância entre 0 e 1. "
"Sua resposta deve começar com 'Pontuação: ' seguida da pontuação numérica, "
"depois forneça sua explicação.\n\nRedação: {redacao}".format(redacao=state["redacao"])
)
]
result = llm.invoke(messages)
try:
state["pontuacao_relevancia"] = extrair_pontuacao(result.content)
except ValueError as e:
print(f"Erro em verificar_relevancia: {e}")
state["pontuacao_relevancia"] = 0.0
return state
def verificar_gramatica(state: State) -> State:
"""Verifica a gramática da redação."""
messages = [
HumanMessage(
content= "Analise a gramática da Língua Portuguesa na seguinte redação. "
"Forneça uma pontuação de gramática entre 0 e 1. "
"Sua resposta deve começar com 'Pontuação: ' seguida da pontuação numérica, "
"depois forneça sua explicação.\n\nRedação: {redacao}".format(redacao=state["redacao"])
)
]
result = llm.invoke(messages)
try:
state["pontuacao_gramatica"] = extrair_pontuacao(result.content)
except ValueError as e:
print(f"Erro em verificar_gramatica: {e}")
state["pontuacao_gramatica"] = 0.0
return state
def analizar_estrutura(state: State) -> State:
"""Analisa a estrutura da redação."""
messages = [
HumanMessage(
content= "Analise a estrutura de acordo com a normal culta da Língua Portuguesa na seguinte redação. "
"Forneça uma pontuação de estrutura entre 0 e 1. "
"Sua resposta deve começar com 'Pontuação: ' seguida da pontuação numérica, "
"depois forneça sua explicação.\n\nRedação: {redacao}".format(redacao=state["redacao"])
)
]
result = llm.invoke(messages)
try:
state["pontuacao_estrutura"] = extrair_pontuacao(result.content)
except ValueError as e:
print(f"Erro em analizar_estrutura: {e}")
state["pontuacao_estrutura"] = 0.0
return state
def avaliar_profundidade(state: State) -> State:
"""Avalia a profundidade de análise na redação."""
messages = [
HumanMessage(
content= "Avalie a profundidade de análise na seguinte redação. "
"Forneça uma pontuação de profundidade entre 0 e 1. "
"Sua resposta deve começar com 'Pontuação: ' seguida da pontuação numérica, "
"depois forneça sua explicação.\n\nRedação: {redacao}".format(redacao=state["redacao"])
)
]
result = llm.invoke(messages)
try:
state["pontuacao_profundidade"] = extrair_pontuacao(result.content)
except ValueError as e:
print(f"Erro em avaliar_profundidade: {e}")
state["pontuacao_profundidade"] = 0.0
return state
def calcular_pontuacao_final(state: State) -> State:
"""Calcula a pontuação final com base nas pontuações dos componentes individuais."""
state["pontuacao_final"] = (
state["pontuacao_relevancia"] * 0.3 +
state["pontuacao_gramatica"] * 0.2 +
state["pontuacao_estrutura"] * 0.2 +
state["pontuacao_profundidade"] * 0.3
)
return state
# Inicializa o StateGraph
workflow = StateGraph(State)
# Adiciona nós ao grafo
workflow.add_node("verificar_relevancia", verificar_relevancia)
workflow.add_node("verificar_gramatica", verificar_gramatica)
workflow.add_node("analizar_estrutura", analizar_estrutura)
workflow.add_node("avaliar_profundidade", avaliar_profundidade)
workflow.add_node("calcular_pontuacao_final", calcular_pontuacao_final)
# Define e adiciona arestas condicionais
workflow.add_conditional_edges(
"verificar_relevancia",
lambda x: "verificar_gramatica" if x["pontuacao_relevancia"] > 0.5 else "calcular_pontuacao_final"
)
workflow.add_conditional_edges(
"verificar_gramatica",
lambda x: "analizar_estrutura" if x["pontuacao_gramatica"] > 0.6 else "calcular_pontuacao_final"
)
workflow.add_conditional_edges(
"analizar_estrutura",
lambda x: "avaliar_profundidade" if x["pontuacao_estrutura"] > 0.7 else "calcular_pontuacao_final"
)
workflow.add_conditional_edges(
"avaliar_profundidade",
lambda x: "calcular_pontuacao_final"
)
# Define o ponto de entrada
workflow.set_entry_point("verificar_relevancia")
# Define o ponto de saída
workflow.add_edge("calcular_pontuacao_final", END)
# Compila o grafo
app = workflow.compile()
def avaliar_redacao(redacao: str) -> dict:
"""Avalia a redação fornecida usando o fluxo de trabalho definido."""
initial_state = State(
redacao=redacao,
pontuacao_relevancia=0.0,
pontuacao_gramatica=0.0,
pontuacao_estrutura=0.0,
pontuacao_profundidade=0.0,
pontuacao_final=0.0
)
result = app.invoke(initial_state)
return result
exemplo_redacao = """[REDACAO_AQUI]"""
# Avalia a redação de exemplo
result = avaliar_redacao(exemplo_redacao)
# Converte as pontuações de 0-1 para 0-10
pontuacao_final = result['pontuacao_final'] * 10
pontuacao_relevancia = result['pontuacao_relevancia'] * 10
pontuacao_gramatica = result['pontuacao_gramatica'] * 10
pontuacao_estrutura = result['pontuacao_estrutura'] * 10
pontuacao_profundidade = result['pontuacao_profundidade'] * 10
# Exibe os resultados
print(f"Pontuação Final da Redação: {pontuacao_final:.2f}/10\n")
print(f"Pontuação de Relevância: {pontuacao_relevancia:.2f}/10")
print(f"Pontuação de Gramática: {pontuacao_gramatica:.2f}/10")
print(f"Pontuação de Estrutura: {pontuacao_estrutura:.2f}/10")
print(f"Pontuação de Profundidade: {pontuacao_profundidade:.2f}/10")Explicação do fluxo:
a - Entrada: começa no nó verificar_relevancia.
b - Se a pontuação de relevância > 0.5, vai para
verificar_gramatica. Caso contrário, vai direto para calcular_pontuacao_final.
c - Em verificar_gramatica:
- Se a pontuação de gramática > 0.6, continua para analizar_estrutura.
- Caso contrário, vai para calcular_pontuacao_final.
d - Em analizar_estrutura:
- Se a pontuação de estrutura > 0.7, segue para avaliar_profundidade.
- Caso contrário, vai para calcular_pontuacao_final.
e - avaliar_profundidade sempre leva para
calcular_pontuacao_final.
f - calcular_pontuacao_final é o último nó antes do fim (END).
Saída:
uv run avalidaor_redacao.py
Pontuação Final da Redação: 8.35/10
Pontuação de Relevância: 9.00/10
Pontuação de Gramática: 8.50/10
Pontuação de Estrutura: 8.50/10
Pontuação de Profundidade: 7.50/1003 - RAG recuperar documentos
Neste exemplo, vamos adicionar alguns documentos ao RAG(Retrieval-Augmented Generation). Assim, de acordo com o que for solicitado, o sistema exibirá informações desses documentos, caso existam; caso contrário, buscará na internet. Segue abaixo o fluxo dos grafos.
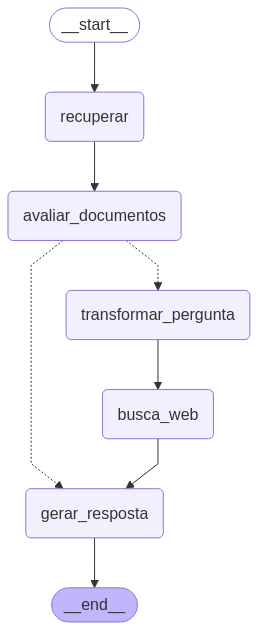
O código implementa um fluxo completo de RAG (Retrieval-Augmented Generation) usando LangChain com documentos científicos da USP e busca web como fallback.
Recebe uma pergunta do usuário e tenta respondê-la com base em documentos previamente carregados e indexados. Se os documentos não forem suficientes, ele reformula a pergunta e realiza uma busca na web. Por fim, gera uma resposta baseada em todos os dados relevantes.
Explicação do Fluxo
- Imports e Configuração Inicial
- Importa bibliotecas do LangChain, dotenv, e ferramentas de busca na Web (Tavily).
- Carrega as variáveis de ambiente, incluindo a chave da Tavily.
- Carregamento e Indexação de Documentos
- Três artigos científicos da Revista de Biologia da USP são baixados.
- O conteúdo é dividido em pedaços menores (chunks).
- Os pedaços são vetorizados e armazenados no ChromaDB.
- É criado um retriever para buscar chunks relevantes com base em similaridade semântica.
- Configuração dos LLMs e Prompts
- Dois modelos da OpenAI são configurados: um para gerar respostas e outro para reescrita e avaliação.
- São definidos prompts:
rag_prompt: Geração da resposta final.
grade_prompt: Avaliação da relevância dos documentos.
re_write_prompt: Reescrita da pergunta para melhorar a busca.
- Ferramenta de busca na web (Tavily) configurada.
- Definição do Estado do Grafo
- Define-se a estrutura do estado compartilhado entre os nós, contendo: pergunta, documentos, resultado da geração, etc.
- Funções dos Nós
- recuperar: Usa o retriever para buscar documentos relevantes.
- avaliar_documentos: Filtra documentos realmente relevantes com LLM.
- transformar_pergunta: Reescreve a pergunta para buscar melhor.
- busca_web: Realiza busca online com Tavily e adiciona os resultados como documentos.
- gerar_resposta: Gera a resposta final com base no contexto (documentos).
- decidir_geracao: Decide se precisa buscar na web com base na relevância dos documentos.
- Construção do Grafo (LangGraph)
- O grafo é construído com os nós acima conectados:
Início: START → recuperar → avaliar_documentos
Condicional: se não há documentos suficientes → transformar_pergunta → busca_web → gerar_resposta
Senão → gerar_resposta → END
- Execução
- Pergunta: "Prevalência e detecção de resistência de Staphylococcus"
- O grafo é executado passo a passo, e os resultados de cada nó são mostrados.
START
↓
[recuperar]
↓
[avaliar_documentos]
↙ ↘
[transformar] [gerar_resposta]
↓
[busca_web]
↓
[gerar_resposta]
↓
ENDCódigo completo:
import os
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.output_parsers import StrOutputParser
from langchain.schema import Document
from langchain import hub
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.graph import END, StateGraph, START
from typing import List
from typing_extensions import TypedDict
from pprint import pprint
# -----------------------------
# Carregar variáveis de ambiente
# -----------------------------
load_dotenv()
os.environ['TAVILY_API_KEY'] = os.getenv("TAVILY_API_KEY")
# -----------------------------
# Carregamento e indexação de documentos
# -----------------------------
urls = [
"https://www.revistas.usp.br/revbiologia/article/view/217747",
"https://www.revistas.usp.br/revbiologia/article/view/206105",
"https://www.revistas.usp.br/revbiologia/article/view/219858",
]
raw_docs = [doc for url in urls for doc in WebBaseLoader(url).load()]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=250, chunk_overlap=0)
doc_chunks = text_splitter.split_documents(raw_docs)
vectorstore = Chroma.from_documents(
documents=doc_chunks,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
llm_main = ChatOpenAI(model_name="gpt-4.1-nano", temperature=0)
llm_advanced = ChatOpenAI(model="gpt-4.1-nano", temperature=0)
rag_prompt = hub.pull("rlm/rag-prompt")
rag_chain = rag_prompt | llm_main | StrOutputParser()
class GradeDocuments(BaseModel):
binary_score: str = Field(description="Os documentos são relevantes à pergunta, 'sim' ou 'não'")
grade_prompt = ChatPromptTemplate.from_messages([
("system", "Você é um avaliador que verifica a relevância de um documento recuperado em relação a uma pergunta do usuário. Responda apenas em português do Brasil."),
("human", "Documento recuperado:\n\n{document}\n\nPergunta do usuário: {question}"),
])
retrieval_grader = grade_prompt | llm_advanced.with_structured_output(GradeDocuments)
re_write_prompt = ChatPromptTemplate.from_messages([
("system", "Você é um reescritor de perguntas que transforma a entrada em uma versão melhor para busca. Responda em português do Brasil."),
("human", "Pergunta inicial:\n\n{question}\n\nFormule uma pergunta melhorada."),
])
question_rewriter = re_write_prompt | llm_advanced | StrOutputParser()
web_search_tool = TavilySearchResults(k=3)
class GraphState(TypedDict):
question: str
generation: str
web_search: str
documents: List[Document]
full_context: str
def recuperar(state):
print(">>> Recuperar documentos")
question = state["question"]
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def avaliar_documentos(state):
print(">>> Avaliar relevância dos documentos")
question = state["question"]
documents = state["documents"]
filtered_docs = []
for doc in documents:
score = retrieval_grader.invoke({"question": question, "document": doc.page_content})
if score.binary_score.lower() == "sim":
filtered_docs.append(doc)
web_search = "Sim" if len(filtered_docs) < 1 else "Não"
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transformar_pergunta(state):
print(">>> Reescrever pergunta")
question = state["question"]
better_question = question_rewriter.invoke({"question": question})
return {"documents": state["documents"], "question": better_question}
def busca_web(state):
print(">>> Buscar na Web")
question = state["question"]
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
state["documents"].append(Document(page_content=web_results))
return {"documents": state["documents"], "question": question}
def gerar_resposta(state):
print(">>> Gerar resposta")
return {
"documents": state["documents"],
"question": state["question"],
"generation": rag_chain.invoke({"context": state["documents"], "question": state["question"]}),
"web_search": state.get("web_search", "Não"),
"full_context": "\n\n".join([doc.page_content for doc in state["documents"]])
}
def decidir_geracao(state):
if state["web_search"] == "Sim":
return "transformar_pergunta"
return "gerar_resposta"
# -----------------------------
# Construção do grafo
# -----------------------------
workflow = StateGraph(GraphState)
workflow.add_node("recuperar", recuperar)
workflow.add_node("avaliar_documentos", avaliar_documentos)
workflow.add_node("transformar_pergunta", transformar_pergunta)
workflow.add_node("busca_web", busca_web)
workflow.add_node("gerar_resposta", gerar_resposta)
workflow.add_edge(START, "recuperar")
workflow.add_edge("recuperar", "avaliar_documentos")
workflow.add_conditional_edges("avaliar_documentos", decidir_geracao, {
"transformar_pergunta": "transformar_pergunta",
"gerar_resposta": "gerar_resposta"
})
workflow.add_edge("transformar_pergunta", "busca_web")
workflow.add_edge("busca_web", "gerar_resposta")
workflow.add_edge("gerar_resposta", END)
app = workflow.compile()
# -----------------------------
# Execução
# -----------------------------
inputs = {"question": "Prevalência e detecção de resistência de Staphylococcus"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Nó '{key}':")
pprint("\n---\n")
# Resposta final
pprint(value["full_context"])Os códigos completos: GitHub
Referências:
LangGraph
Agent AI with LangGraph: A Modular
Framework for Enhancing Machine Translation
Using Large Language Models
LiteLLM
Corrective Retrieval Augmented Generation
UV
Scoras Academy


