When you have a monolith, you’ve got one big problem to solve. Switch to microservices, and now you’ve got 99 smaller problems—plus a distributed system.
Maintaining reliability with microservices distributed systems are challenging. This playbook explores the risks involved, the theory why, how to measure, alert and predict reliability and how to mitigate using architectural patterns.
Microservices Reliability Playbook
- Introduction to Risk
- Introduction to Microservices Reliability
- Microservices Patterns
- Read Patterns
- Write Patterns
- Multi-Service Patterns
- Call Patterns
Download the full Playbook at a free PDF
Introduction
I first learned about microservices in 1998. Yes, a quick search will reveal microservices as a name was introduced in 2011-12, attributed to Martin Fowler and James Lewis. Yet, in 1998 I read a book by James R. Callan about collaborative computing from which I learned all about microservices, 13 years before they were named.
I joined Wix in 2010 to figure out what the iTab is and how the company's product can work on mobile. However, by the end of the year I have transitioned to join the team building Wix Infrastructure with Eugene Olshenbaum, Aviran Mordo and the rest of Wix Engineering.
With this work, we will explore why we should be using microservices, how large they should be, what are the risk factors when using microservices, how to mitigate those risks, how to monitor microservices and guidelines to build reliable microservices systems.
To understand microservices, we first need to understand how they evolved. In the 90s, we have been using what is now called 2 tier applications - a desktop application connected to a central database (it was before the time of web or mobile applications).
Those desktop applications had to contain all the functionality, from all the UI to all the business logic, and in some cases database migration logic (for lazy migrations). Developing those applications was very productive using tools like Visual Basic, Delphi and later C#.
However, as the application grows and the number of developers grows to over 10, the effects of working in a monolith emerge - different teams are not ready at the same time, efforts for merging work, different assumptions on the database, etc.
Late 90s and the early 2000s, we moved to 3-tier applications, placing a server between the desktop application and the database. This server decoupled the business logic from the UI, allowing for two teams to work in parallel. Yet, with application and complexity growth, it was clear we need a more robust pattern.
From the mid to late 2000s, the shift to web applications created modular client applications, as each web page is independent. Microservices emerged at the same time to decouple backend development and enable scaling the team, as well as create smaller blast radii in case of a problem.
But what is the underlying cause for those shifts and what are we solving?
Risk!
Risks in Software
Risk in software is defined as the chance that given a deployed software system will fail to function, due to any reason. There are 4 types of risks for software systems
Malfunctions
Malfunctions happen when some infrastructure breaks, such as the hardware, network, electricity, the cloud provider has an outage or similar. Obviously, if such a thing happens, our software system will fail to function.
Some Software systems are designed to be resilient to malfunctions (most notably IP networks) by deploying adaptive routing algorithms and making a design decision of no global true state.
In most cases, when building software systems we assume our infrastructure is reliable, or we handle malfunctions using availability zones or multiple regions (for cloud applications) and multiple data centers (for on prem systems) and switching from one to the other in case of malfunction.
Security
Risk from security incidents is the risk of someone, employee or a 3rd party, going into the system and preventing it from working, partially or as a whole. Ransomware attacks are just one such example.
Another type of security risk is data breaches, at which someone uses a software or access vulnerability to steal data or proprietary information.
Malicious users can also abuse a system, using it for unintended intents such as attacking other systems, impersonating, consuming unintended resources, etc.
Normally, security teams deploy different measures to prevent those types of risks, which we will not expand on in this playbook.
Change
The risk of change is the risk caused when a team of developers deploy a software change. With the change, on every deployment, they have a chance to
- Introduce a bug
- Introduce a breaking change some other component is not ready for (dependencies)
- Introduce additional CPU / IO / memory load the deployment is not ready for (application load)
- Broken deployment
- Adversely affect other components in other systems which may seem unrelated to the original deployment (also denoted as blast radii of the failure)
This is the type of risk microservices aim to solve.
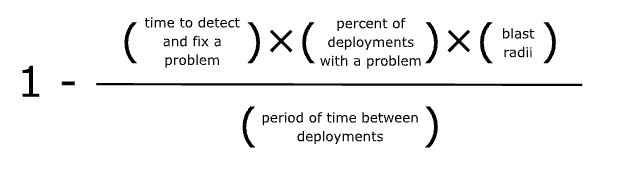
We can calculate the reliability due to risk of change of a component using the following formula:
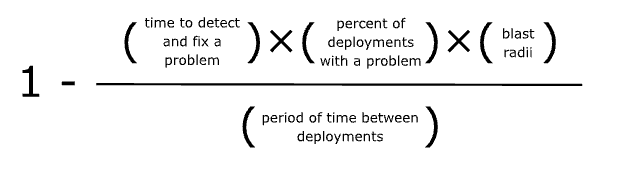
- “Percent of deployments with a problem” - can be mitigated using methodologies like TDD (test driven development), lab deployments and manual QA.
- “Blast radii” - is given a problem, how much of the overall system is affected?
- “Time to detect and fix a problem” - can be mitigated using modern monitoring and alerting tools as well as having fast automated deployment pipeline
Microservices aims to reduce the “blast radius” of a problem. Continuous Delivery aims to reduce the size of a change and those reduce the “percent of deployments with a problem” as well as the “blast radius”. Overall, both reduce the risk of change.
Load and Latency
The risk from load and latency is the risk that given two processes (two microservices, server and database, client and server, or any other two), the call from the first to the second will delay up to a timeout due to different loads and latencies in the places we do not see.
To understand load and latency, one just needs to consider what happens between two adjacent cloud hosts - which appears virtually to be side by side. The reality is they are probably on different locations in the cloud data center, and the packets get translated from the virtual network IP address to the physical network IP address, goes through a switch, a few routers, a switch again, target network stack and process. All the devices and layers deploy queues for load management, which most of the time offer quick response, yet sometimes offer really slow response.
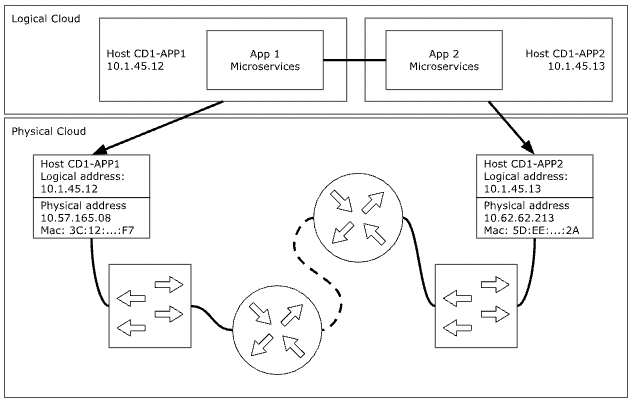
The result is similar to a Log-Normal distribution with a cutoff after which higher latency numbers have higher probability due to how queues are working. In this work we use a model based on Log-Normal distribution (μ=0.5, 𝝈=0.7) with a cutoff at 20ms, which effectively gives five-nines network (latency probability of 0.99999 to be below 20ms). The probability is visualized below.
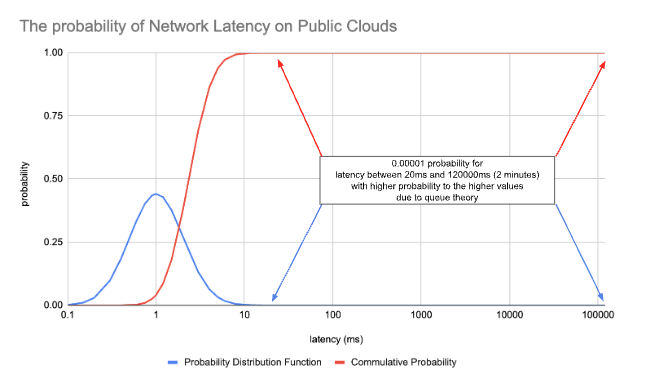
To summarize load and latency risk, two micro services communicate at a five-nines reliability, but will fail to communicate at 0.00001 probability.
Next: Microservices Reliability Playbook, Part 2 - Introduction to Microservices Reliability