Satya Nadella, Microsoft's CEO, discusses AI agents and quantum technology in an interview on the South Park Commons YouTube channel. At 29:36, he says the world is too messy for SQL to work, which might be surprising, as SQL serves as an API for relational databases, built to store various types of data, including the most complex.
This reminds me of some challenges I encountered with the relational model. I will share a real-life example from many years ago when I worked as a data architect at an airline company before the rise of document databases to resolve such issues.
Flights have an airport of origin and an airport of destination. This is a typical case where one table has multiple aliases in a query because of the two different roles. In a relational database, the table of flights has two columns with a foreign key that references a table of airports: origin airport and destination airport. There are already many questions that can start a debate with relational data modelers:
Should we use singular ("flight") or plural ("flights") for table names
Should we name the columns with the role first or last: destination airport ("DST_ARP") or airport of destination ("ARP_DST")
What are the keys? The foreign key can use the IATA code to avoid joins in many queries or a surrogate key in case the IATA code changes, but with two additional joins for the queries
What are the tables? How many tables are needed to store this information, normalized for easier updates or denormalized for simpler queries?
In a document model, we can store all relevant information together. An "airport" collection will contain one document per airport, detailing its IATA code, name, city, latitude, longitude, country code, and country name, all neatly organized in sub-documents.
Here is an example of a document that describes Amsterdam's Airport
{
"_id": "AMS",
"name": "Amsterdam Airport Schiphol",
"location": {
"city": {
"name": "Amsterdam",
"country": {
"name": "Netherlands",
"code": "NL"
}
},
"coordinates": {
"latitude": 52.308613,
"longitude": 4.763889
}
},
"iata": "AMS",
"icao": "EHAM",
"is_hub_for_airline": ["KLM", '"Air France"],
"timezone": "Europe/Amsterdam",
"type": "international",
"runways": [
{
"name": "18R/36L",
"length_meters": 3800
},
{
"name": "06/24",
"length_meters": 3500
}
],
"website": "https://www.schiphol.nl/"
}In a relational database, because of the One-To-Many relationships and to obey the first Normal Form, the same data is scattered to multiple tables:
INSERT INTO Countries (country_id, name, code)
VALUES (1, 'Netherlands', 'NL');
INSERT INTO Cities (city_id, name, country_id)
VALUES (1, 'Amsterdam', 1);
INSERT INTO Airports (airport_id, name, city_id, iata, icao, timezone, type, website)
VALUES ('AMS', 'Amsterdam Airport Schiphol', 1, 'AMS', 'EHAM', 'Europe/Amsterdam', 'international', 'https://www.schiphol.nl/');
INSERT INTO Coordinates (airport_id, latitude, longitude)
VALUES ('AMS', 52.308613, 4.763889);
INSERT INTO Runways (airport_id, name, length_meters)
VALUES ('AMS', '18R/36L', 3800), ('AMS', '06/24', 3500);A relational table has a fixed structure that must be declared before inserting data:
CREATE TABLE Countries (
country_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
code CHAR(2) NOT NULL UNIQUE
);
CREATE TABLE Cities (
city_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
country_id INT,
FOREIGN KEY (country_id) REFERENCES Countries(country_id)
);
CREATE TABLE Airports (
airport_id CHAR(3) PRIMARY KEY,
name VARCHAR(100) NOT NULL,
city_id INT,
iata CHAR(3) NOT NULL UNIQUE,
icao CHAR(4) NOT NULL UNIQUE,
timezone VARCHAR(50) NOT NULL,
type VARCHAR(50),
website VARCHAR(100),
FOREIGN KEY (city_id) REFERENCES Cities(city_id)
);
CREATE TABLE Coordinates (
airport_id CHAR(3),
latitude DECIMAL(9,6) NOT NULL,
longitude DECIMAL(9,6) NOT NULL,
PRIMARY KEY (airport_id),
FOREIGN KEY (airport_id) REFERENCES Airports(airport_id)
);
CREATE TABLE Runways (
runway_id INT PRIMARY KEY AUTO_INCREMENT,
airport_id CHAR(3),
name VARCHAR(10) NOT NULL,
length_meters INT NOT NULL,
FOREIGN KEY (airport_id) REFERENCES Airports(airport_id)
);Declaring foreign keys is essential to ensure referential integrity, which isn't required when modeling in a single document since the relationship is inherent in the data structure.
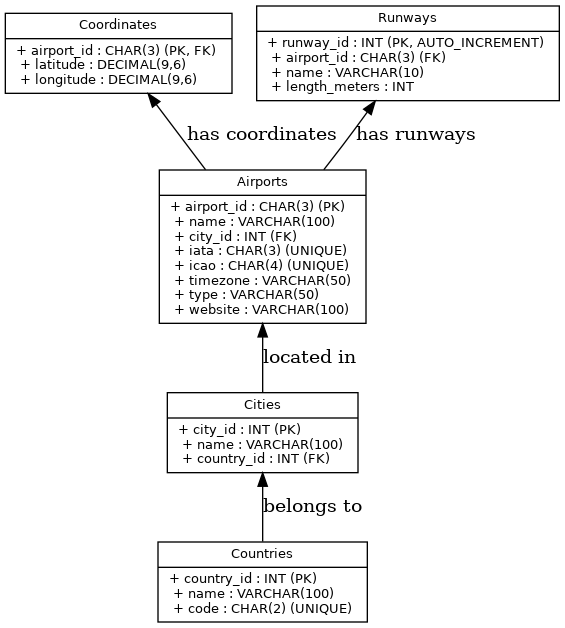
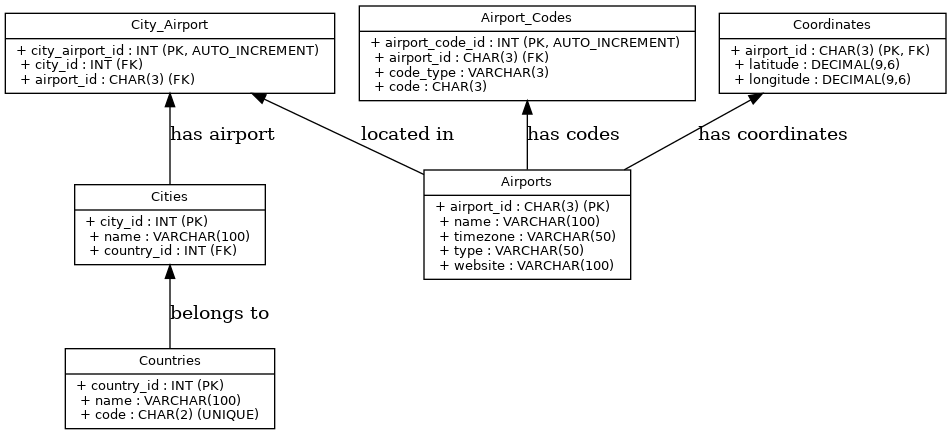
With numerous tables, an ERD diagram aids in illustrating the structure:
Welcome to Ou Messy World
This data model works well when a city is assigned an airport, which is usually true. You can develop numerous applications based on this model until a significant issue emerges: your flight schedule features a new international airport, EuroAirport Basel Mulhouse Freiburg, which this model cannot accommodate. This airport is physically in France, but you can drive to Basel without crossing any border, so it is also in Switzerland.
This airport is unique, bi-national, serving Basel in Switzerland and Mulhouse in France. It has multiple IATA codes: EAP, as well as MLH and BSL for each country. This necessitates a structural change to the relational data model because the relationship between airports and cities must be a Many-to-Many:
CREATE TABLE Countries (
country_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
code CHAR(2) NOT NULL UNIQUE
);
CREATE TABLE Cities (
city_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
country_id INT,
FOREIGN KEY (country_id) REFERENCES Countries(country_id)
);
CREATE TABLE Airports (
airport_id CHAR(3) PRIMARY KEY,
name VARCHAR(100) NOT NULL,
timezone VARCHAR(50) NOT NULL,
type VARCHAR(50),
website VARCHAR(100)
);
CREATE TABLE Airport_Codes (
airport_code_id INT PRIMARY KEY AUTO_INCREMENT,
airport_id CHAR(3),
code_type VARCHAR(3) CHECK (code_type IN ('EAP', 'BSL', 'MLH')),
code CHAR(3),
FOREIGN KEY (airport_id) REFERENCES Airports(airport_id)
);
CREATE TABLE City_Airport (
city_airport_id INT PRIMARY KEY AUTO_INCREMENT,
city_id INT,
airport_id CHAR(3),
FOREIGN KEY (city_id) REFERENCES Cities(city_id),
FOREIGN KEY (airport_id) REFERENCES Airports(airport_id)
);
CREATE TABLE Coordinates (
airport_id CHAR(3),
latitude DECIMAL(9,6) NOT NULL,
longitude DECIMAL(9,6) NOT NULL,
PRIMARY KEY (airport_id),
FOREIGN KEY (airport_id) REFERENCES Airports(airport_id)
);Inserting a single airport data requires more statements per transaction:
-- Insert into Countries
INSERT INTO Countries (country_id, name, code) VALUES
(1, 'Switzerland', 'CH'),
(2, 'France', 'FR');
-- Insert into Cities
INSERT INTO Cities (city_id, name, country_id) VALUES
(1, 'Basel', 1),
(2, 'Mulhouse', 2);
-- Insert into Airports
INSERT INTO Airports (airport_id, name, timezone, type, website) VALUES
('EAP', 'EuroAirport Basel Mulhouse Freiburg', 'Europe/Zurich', 'international', 'https://www.euroairport.com/');
-- Insert into Airport_Codes
INSERT INTO Airport_Codes (airport_id, code_type, code) VALUES
('EAP', 'EAP', 'EAP'),
('EAP', 'BSL', 'BSL'),
('EAP', 'MLH', 'MLH');
-- Insert into City_Airport
INSERT INTO City_Airport (city_id, airport_id) VALUES
(1, 'EAP'),
(2, 'EAP');
-- Insert into Coordinates
INSERT INTO Coordinates (airport_id, latitude, longitude) VALUES
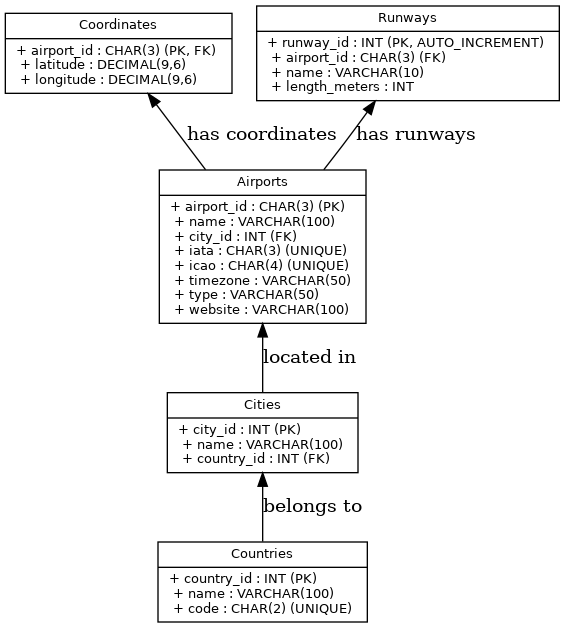
('EAP', 47.59, 7.529167);The Entity-Relationship Diagram (ERD) shows an additional table for the Many-to-Many relationship between airports and cities:
All other airports must use the new model, even if they have only one city per airport. Having a model that distinguishes the two possibilities of One-to-Many and Many-to-Many would be even more complex, with inheritance leading to more tables.
Modifying such a data model affects all existing code, requiring all queries to be rewritten with a new join. In practice, this modification is too risky, leading to the implementation of some workarounds for legacy code. For instance, I've seen an application with a dummy city for Basel+Mulhouse and a dummy country for Switzerland+France. Other applications ignored the multi-city property and added a BSL-MLH dummy flight with a zero-kilometer distance and a zero-minute flight duration, which had unexpected side effects. These workarounds leverage the existing code for single-city airports, ensuring that only the new code is impacted by the new airport. However, the data model no longer reflects the real world, and the ideal normalized model that is supposed to avoid anomalies is broken.
This is where the world is too messy for SQL: a normalized data model must include all possibilities, with one model shared by all objects, including the nominal case and the diversity of edge cases. Everything can be represented with normalized tables, but in practice, applications break this model for more flexibility. Many applications that adapt to different domains opted for an Entity-Attribute-Value model to get more agility, but at the price of the worst performance because the SQL query planner of a relational database is not built to optimize such key-value data access. If you have never encountered such schema or wonder what the problem is, I recommend this old story by Tim Gorman about a single "DATA" table model: bad carma.
Document Data Modeling Flexibility
With a document model, two documents of the same collection do not strictly need to adhere to the same structure. I can keep the existing structure and code for the single-city airports and use an array instead of a single value when inserting the bi-national airport:
{
"_id": "EAP",
"name": "EuroAirport Basel Mulhouse Freiburg",
"location": {
"city": [
{
"name": "Basel",
"country": {
"name": "Switzerland",
"code": "CH"
}
},
{
"name": "Mulhouse",
"country": {
"name": "France",
"code": "FR"
}
}
],
"coordinates": {
"latitude": 47.59,
"longitude": 7.529167
}
},
"iata": [ "EAP", "BSL", "MLH" ],
"timezone": "Europe/Zurich",
"type": "international",
"website": "https://www.euroairport.com/"
}Such a format may require additional code when the business logic differs between single and multi-city airports. Still, there's no need to change the existing code and reformat the existing data. The additional complexity due to the "messy" world has a scope limited to its new context and does not undermine the entirety of the existing data model.
Examples like this can create the impression that the relational model is too rigid. Although normalization was designed to facilitate model evolution, and SQL databases have reduced the downtime for some ALTER statements, it still restricts all data to a single model. Minor changes in business can break existing code and significantly increase the complexity of the data model. A normalized relational model makes adding a column to a table easy. However, when the keys or the association cardinality changes, the relational model requires impactful modification with lots of code to modify and test, and there is downtime during the schema migration.
Document Data Modeling and MongoDB API
Document data modeling allows you to add documents even if their structure diverges from the collection's existing documents. The structure can still be constrained with schema validation, but with more agility than what SQL relational tables definition provide.
Here is an example of schema validation that accepts the two document types - note the "oneOf" sections:
db.runCommand({
collMod: "airports",
validator: {
$jsonSchema: {
bsonType: "object",
required: ["_id", "name", "location", "iata", "timezone", "type", "website"],
properties: {
...
"location": {
bsonType: "object",
required: ["city", "coordinates"],
properties: {
"city": {
oneOf: [
{
bsonType: "object",
required: ["name", "country"],
...
},
{
bsonType: "array",
items: {
bsonType: "object",
required: ["name", "country"],
...
}
}
]
},
...
}
},
"iata": {
oneOf: [
{
bsonType: "string",
description: "must be a string or an array of strings and is required"
},
{
bsonType: "array",
items: {
bsonType: "string"
}
}
]
},
...
}
}
}
});With schema validation, you can combine the schema flexibility with schema integrity constraints. It is recommended that schema validation be added so that the MongoDB database can guarantee that the documents have the fields expected by the application code.
Additionally, the MongoDB API prioritizes developer experience for the application evolutions. Such polymorphic schema may not need different code. I have inserted the two documents described above into an "airports" collection, and the code to find a country's airports is the same whether the city attribute is one sub-document or an array
mdb> // find airports in Netherlands
mdb> db.airports.find({
"location.city.country.name": "Netherlands"
},{
"name": 1
});
[ { _id: 'AMS', name: 'Amsterdam Airport Schiphol' } ]
mdb> // find airports in France
db.airports.find({
"location.city.country.name": "France"
},{
"name": 1
});
[ { _id: 'EAP', name: 'EuroAirport Basel Mulhouse Freiburg' } ]
mdb> // find airports in Switzerland
db.airports.find({
"location.city.country.name": "Switzerland"
},{
"name": 1
});
[ { _id: 'EAP', name: 'EuroAirport Basel Mulhouse Freiburg' } ]
mdb>With MongoDB, you don't have to change the query. You also do not have to change the index definition. I have created an index on the country name:
mdb> db.airports.createIndex(
{ "location.city.country.name": 1 }
);
location.city.country.name_1When having only single-city airports in the collection, the execution plan for the find query shows:
stage: 'IXSCAN',
keyPattern: { 'location.city.country.name': 1 },
indexName: 'location.city.country.name_1',
isMultiKey: false,
multiKeyPaths: { 'location.city.country.name': [] },
indexBounds: {
'location.city.country.name': [ '["Netherlands", "Netherlands"]' ]
}Once a multi-city airport has been added, it switches to a multi-key index:
stage: 'IXSCAN',
keyPattern: { 'location.city.country.name': 1 },
indexName: 'location.city.country.name_1',
isMultiKey: true,
multiKeyPaths: { 'location.city.country.name': [ 'location.city' ] },
indexBounds: {
'location.city.country.name': [ '["Netherlands", "Netherlands"]' ]
}MongoDB multi-key indexes simply index more than one value per document when the cardinality changes from One-to-One to One-to-Many.
You may think that using a JSON data type in an SQL database gives you the same advantages. However, query planning and indexing are significant differences between document databases like MongoDB and storing documents in a relational database like PostgreSQL.
PostgreSQL's JSONB is a data type that enables schema-less data storage. Using an expression index, you can create an index for a specific key in the document, provided it is known in advance (schema-on-write) and is a single key without an array in the path. However, you must use an inverted index when the path includes an array. GIN indexes, optimized for indexing unknown sub-paths (schema-on-read), are inverted indexes and can be used with arrays (see Indexing JSON in PostgreSQL). Still, they do not provide all the features of regular indexes. For example, the result from a GIN index in PostgreSQL is not sorted and cannot be used to optimize an ORDER BY ... LIMIT. When the schema-on-write involves a one-to-many relationship, storing it in normalized columns in a separate table and joining it at the time of the query is often recommended.
MongoDB is a database that natively indexes document paths, so you don't need this double data modeling approach. Regular indexes can be used on the schema-on-write part of the document, even when the path includes an array, and provide the full Equality, Sort, Range experience. Those indexes follow the flexibility of the document model, where not only new fields can be added, but a One-to-One can become a One-to-Many without adding more complexity. For the schema-on-read part, where the structure is unknown before the query, you can use the same indexes with wildcards to index all keys.
Satya Nadella's interview was about AI foundation models. MongoDB has search indexes for schemaless text or embeddings, but regular indexes are still used for exact searches on structured schemas. When the world is too messy for SQL, MongoDB excels by avoiding a one-size-fits-all data model. Instead, it provides a domain-driven model tailored to specific access patterns, accommodating new complex outlier business rules without complicating the existing structure, code, and index definition.