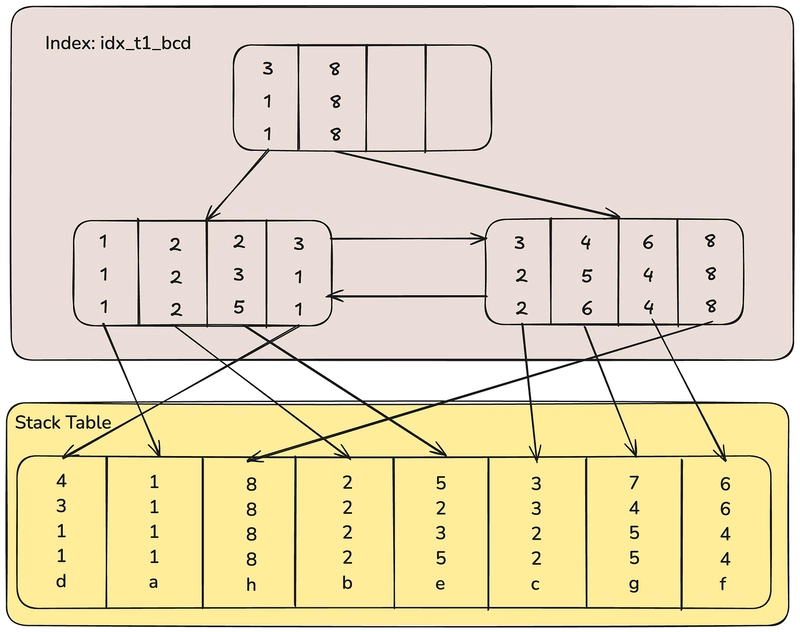
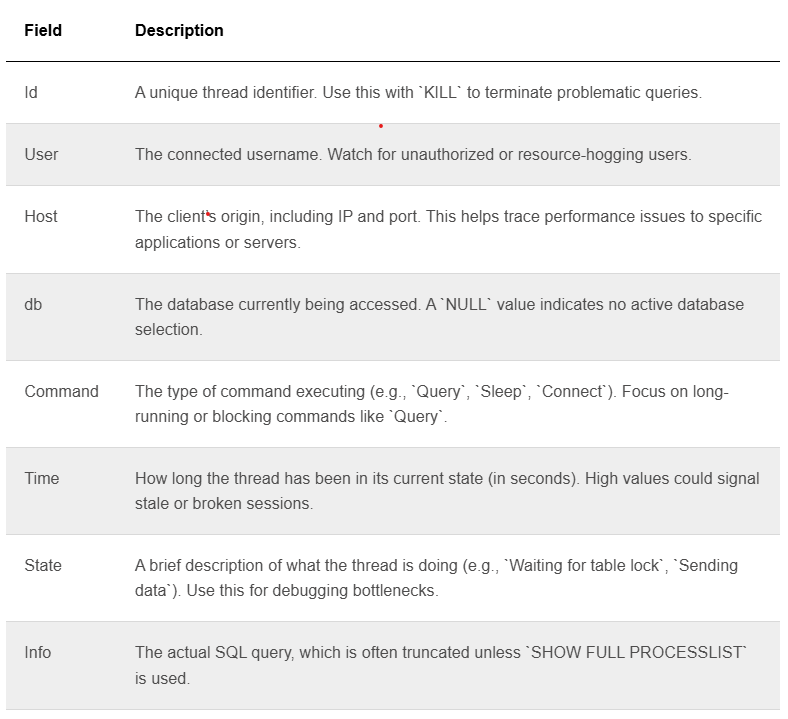
Partitioning is the process of dividing a large database table into smaller. Database partitioning can be broadly categorized into two types -
𝗛𝗼𝗿𝗶𝘇𝗼𝗻𝘁𝗮𝗹 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 - It divides large tables across multiple storage nodes based on region, such as East, West, and South.
𝗩𝗲𝗿𝘁𝗶𝗰𝗮𝗹 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 - It separates sensitive data from core data based on access patterns.
𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗞𝗲𝘆 𝗕𝗲𝗻𝗲𝗳𝗶𝘁𝘀
→ Distributes data across multiple storage nodes for better scalability.
→ Enhances data manageability by segmenting large datasets
→ Enables parallel query execution, improving performance
→ Optimizes physical data storage structure for efficient access
𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝗗𝗶𝘀𝗮𝗱𝘃𝗮𝗻𝘁𝗮𝗴𝗲𝘀
→ 𝗜𝗻𝗰𝗿𝗲𝗮𝘀𝗲𝗱 𝗰𝗼𝗺𝗽𝗹𝗲𝘅𝗶𝘁𝘆 in schema design and query logic
→ 𝗜𝗺𝗽𝗿𝗼𝗽𝗲𝗿 𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 can cause data skews or hotspots
→ 𝗖𝗿𝗼𝘀𝘀-𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻 𝗾𝘂𝗲𝗿𝗶𝗲𝘀 may be slower
→ 𝗠𝗮𝗶𝗻𝘁𝗮𝗶𝗻𝗶𝗻𝗴 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 across partitions is harder