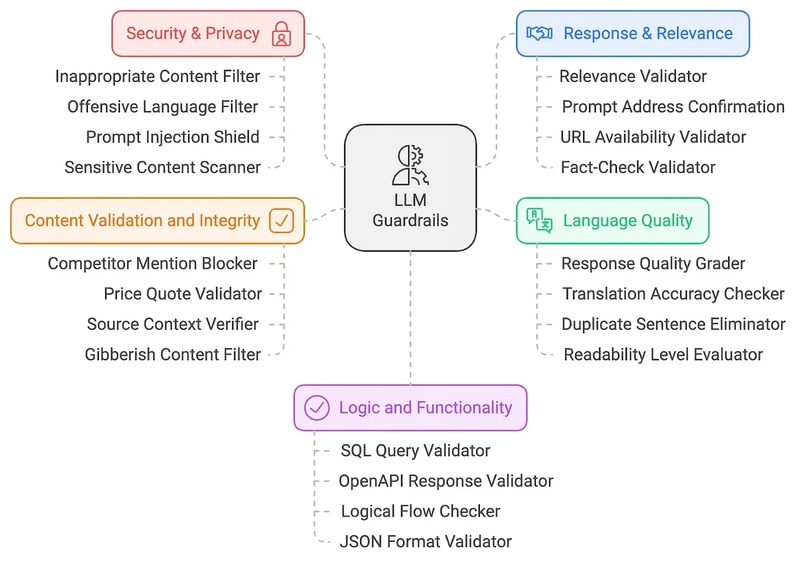
Understanding Reciprocal Rank Fusion (RRF) in Retrieval-Augmented Systems
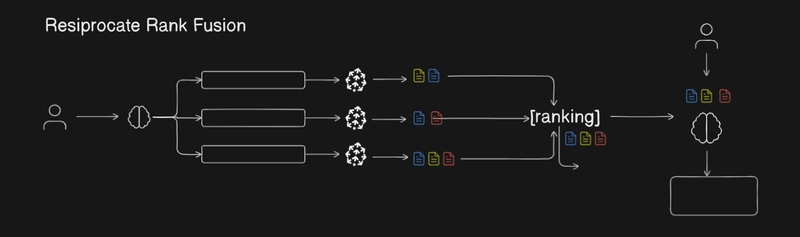
In our last discussion, we explored how Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by fetching external information to improve their responses.Today, let's dive deeper ...