This is a guest author post from community contributor Markus Wildgruber.
My last two articles on aggregation pipelines with MongoDB and C# focussed on the basics of running aggregation pipelines, and presented ways to handle complex aggregation pipelines. This time, we will take a look at several aggregation pipeline stages and how you can use them to implement common scenarios in C#.
Instead of using LINQ, we will use the fluent interface so you know exactly how the MongoDB C# driver will serialize the pipeline when it is sent to the database.
One of the main goals is to make good use of the static types that C# provides so that we define the stages in a type-safe manner and can also use the results seamlessly after the aggregation.
The samples that are used throughout this article are based on the movies collection in the samples_mflix database. We will use the following data transfer object (DTO) class as a starting point:
[BsonIgnoreExtraElements]
public class Movie
{
[BsonRepresentation(MongoDB.Bson.BsonType.ObjectId)]
public string Id { get; set; } = ObjectId.GenerateNewId().ToString();
[BsonElement("title")]
public string Title { get; set; } = string.Empty;
[BsonElement("cast")]
public List<string> Cast { get; set; } = new();
}Calculating properties
One of the great benefits of an aggregation pipeline is that you can calculate values based on the document contents. For instance, you might want to return not all elements of a sub-array, but only three of them. Suppose you want to display the movies in a list that provides limited space. Instead of showing all actors in the cast, a maximum of three can be displayed. In order to reduce the amount of data that is transported from the database to the API, you want to limit the number of array elements directly in the aggregation pipeline:
var result = await movies.Aggregate()
// Match or other stages
.Set(x => new Movie()
{
Cast = x.Cast.Take(3).ToList(),
})
.ToListAsync();The above sample uses a $set stage and takes only the first three actors in the cast array. In the result, all the other properties of the movie document (that are mapped in the class definition) are still contained; the result is a list of Movie objects.
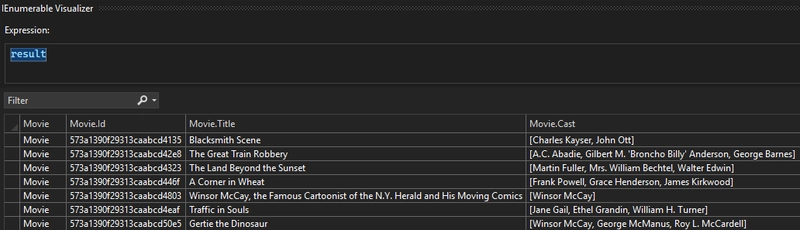
This image shows the first results—the second movie, “The Great Train Robbery,” has four actors in the database, but only three in our result:
What if you want to add a new property in a type-safe way? Say you want to include a flag that shows that there are more actors available. You could create a type that adds this specific flag by just deriving a class from Movie:
[BsonIgnoreExtraElements]
[BsonNoId]
public class MovieWithActorsFlag : Movie
{
public bool HasMoreActors { get; set; }
}The following pipeline will provide the results:
var result = await movies.Aggregate()
.Set(x => new Movie()
{
Cast = x.Cast ?? new List<string>()
})
.Set(x => new MovieWithActorsFlag()
{
HasMoreActors = x.Cast.Count > 3,
Cast = x.Cast!.Take(3).ToList(),
})
.As<MovieWithActorsFlag>()
.ToListAsync();The first Set stage is used to initialize the Cast array if it is null. Otherwise, the call to Count will fail as the $size operator needs an array as input and does not handle null well. Please also note that Set itself does not do a type conversion—hence the call to As as the last stage of the pipeline. This method is very handy in case you need to ensure that the data in the pipeline is mapped to the corresponding C# POCOs.
Projecting to a different form
In the last section, we had a look at how to add calculated properties to a result. But what if you want to reduce the schema to return just the properties that your use case requires? Let's stick with the example of showing a list of movies with the top three actors and a hint that there are more actors. To restrict the amount of data that is returned, we would use a $project stage or the following C# code:
[BsonIgnoreExtraElements]
public class MovieListItem
{
[BsonRepresentation(MongoDB.Bson.BsonType.ObjectId)]
public string Id { get; set; } = ObjectId.GenerateNewId().ToString();
[BsonElement("title")]
public string Title { get; set; } = string.Empty;
[BsonElement("cast")]
public List<string> Cast { get; set; } = new();
public bool HasMoreActors { get; set; }
}
var result = await movies.Aggregate()
.Set(x => new Movie()
{
Cast = x.Cast ?? new List<string>()
})
.Project(x => new MovieListItem()
{
Id = x.Id,
Title = x.Title,
Cast = x.Cast!.Take(3).ToList(),
HasMoreActors = x.Cast.Count > 3,
})
.ToListAsync();In contrast to the previous code, we need to set all properties that we want to be included in the result. However, as our goal is to reduce the amount of data, there should not be too many.
Adding information from other collections
Let's assume that we want to display the details of a movie along with the comments for that movie. As before, we create POCOs to hold the information:
[BsonIgnoreExtraElements]
[BsonNoId]
public class Comment
{
[BsonElement("movie_id")]
[BsonRepresentation(BsonType.ObjectId)]
public required string MovieId { get; set; }
[BsonElement("name")]
public string Name { get; set; } = string.Empty;
[BsonElement("text")]
public string Text { get; set; } = string.Empty;
}
[BsonIgnoreExtraElements]
public class MovieWithComments : Movie
{
public List<Comment> Comments { get; set; } = new();
}Now, we can use Lookup to retrieve the comments with the movie:
var comments = db.GetCollection<Comment>("comments");
var details = await movies.Aggregate()
.Match(x => x.Title == "The Wizard of Oz")
.Lookup<Movie, Comment, MovieWithComments>(comments, x => x.Id, x => x.MovieId, x => x.Comments)
.ToListAsync();Please keep in mind that $lookup is an expensive operation in terms of performance so you should not use it on large amounts of data. As you have already heard for sure, MongoDB offers a flexible data schema that makes it easy to prepare data in the form that supports your application best. The decision of how to handle relationships in your data schema is a very important one and there are several patterns available that you can apply to depict relationships between your data entities.
Paging data with a single request
In order to use bandwidth responsibly, applications often display only a subset of the data to the user and use paging to retrieve data one page after the other. The user can "turn the pages" and load the next set of documents. In addition, the total count of documents that fulfill the current filter criteria is displayed. This often means that two queries are run against the database: one to get the count of documents and another to get the data of the current page. Of course, it would be more efficient to get both results in a single request to the database. This is where the $facet stage comes in; it allows splitting the aggregation pipeline and finishing the pipeline with several different sub-pipelines. The results of the sub-pipelines are returned as a single result at the end—exactly what we need for an efficient implementation of the paging request.
The following piece of code first creates two pipelines for the facets: one for the count and another one that retrieves the data for page six:
var pipelineCount = new EmptyPipelineDefinition<Movie>()
.Count();
var facetCount = AggregateFacet.Create("count", pipelineCount);
var pipelinePage = new EmptyPipelineDefinition<Movie>()
.Sort(Builders<Movie>.Sort.Ascending(x => x.Title))
.Skip(50)
.Limit(10);
var facetPage = AggregateFacet.Create("page", pipelinePage);Afterward, these facets are appended to a pipeline that filters the documents:
var pageResult = await movies.Aggregate()
.Match(x => x.Title.StartsWith("The "))
.Facet(facetCount, facetPage)
.SingleAsync();
var count = pageResult.Facets[0].Output<AggregateCountResult>().Single();
var page = pageResult.Facets[1].Output<Movie>().ToList();Of course, there are lots of other use cases for $facet besides paging that benefit from reducing the number of requests to the database.
Summary
These samples show how to integrate MongoDB aggregations with C# in a type-safe way so that both MongoDB and C# can play to their strengths. The MongoDB C# driver offers lots of other aggregation methods that you can use to set up aggregation pipelines. If this is not enough, check out my article on handling complex aggregation pipelines with C# that shows how to include aggregation pipeline stages in JSON notation.
Which aggregation pipeline stages do you use most often? Are there cases that you wish should be supported in the driver? Let us know in the comments!
